读完这个目录里所有关于 OpenClaw 的文章后,我发现一个很有意思的现象。
前期热度文章里,很多人把重点放在“它能干什么”“多快能装起来”“怎么用起来最爽”。真正开始谈技术骨架、安全边界、长期维护成本的内容,大多出现在热度中后段,或者干脆出现在反思稿里。
这个顺序很容易让人误解。
大家会先听到“AI 员工”“龙虾军团”“24/7 自动化”,然后才会慢慢意识到,这套系统背后有一个完整的工程世界。这个世界里有网关、有消息通道、有模型选择、有权限设计、有 prompt 分层、有多 agent 协作、有定时任务、有日志、有崩溃恢复、有成本控制。
更关键的是,这个世界里还有很多不性感,但很致命的问题:
- 你给的权限越多,它一旦出错能造成的破坏就越大
- 你让它自治的程度越高,它自我进化的不可控性就越强
- 你接的通道越多,你就越难追踪它到底干了什么
- 你存的记忆越多,上下文就越容易污染或膨胀
- 你依赖的技能越多,你就越难判断哪个环节出了问题
这篇文章我不想重复“它有多好用”。这种话已经很多人说过了。我想聊的是更现实、更少被公开讨论,但对你做长期决策影响更大的三个问题:
- OpenClaw 的技术骨架到底是什么样的
- 这套系统的边界和风险在哪里
- 如果你真打算长期养,需要准备付出什么成本
从九层 Prompt 到单 Gateway 多 Agent:OpenClaw 的技术骨架长什么样
很多人第一次接触 OpenClaw,会觉得它像个会聊天的小龙虾。可一旦你开始认真配置、扩展、甚至做多 agent 协作,你很快会发现,自己面对的是一整个系统。
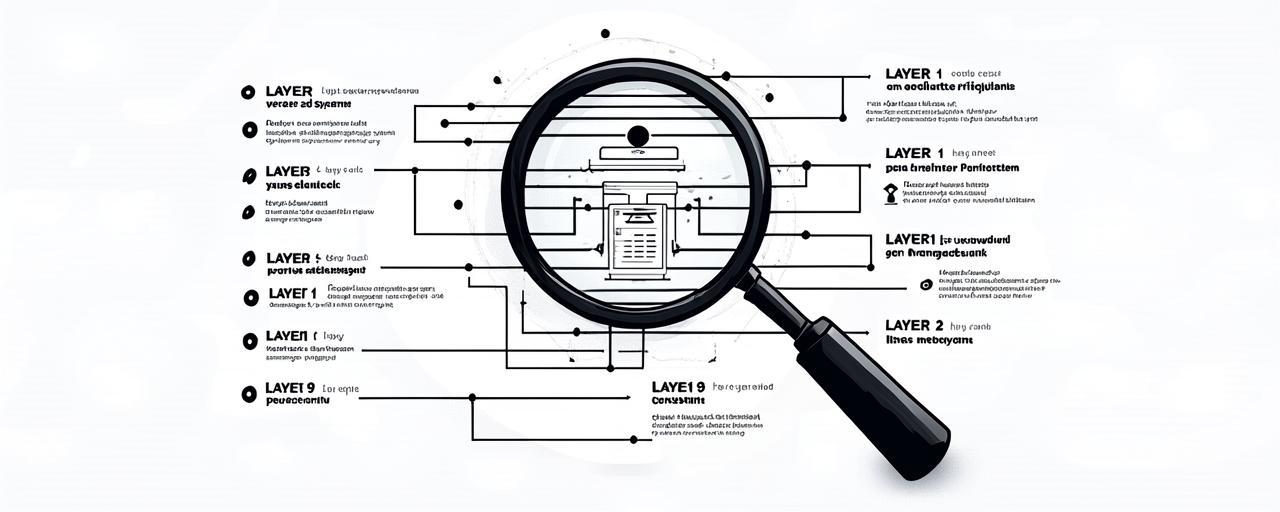
这个系统大概长这样。
一,九层 System Prompt 架构:LLM 的输入远不止你一句话
huangserva 那篇《OpenClaw Agent System Prompt 架构详解(9 层)》把这件事讲得很透。
你每次跟 OpenClaw 说一句话,它真正发给模型的输入至少包含九层内容:
- Layer 1:框架代码和基础上下文
- Layer 2:运行时状态
- Layer 3:会话历史与崩溃恢复信息
- Layer 4:工具定义与可用性
- Layer 5:工作区文件(SOUL.md、USER.md、MEMORY.md、HEARTBEAT.md 等)
- Layer 6:Bootstrap 动态注入内容
- Layer 7:Skill 文件和配置
- Layer 8:当前会话的上下文
- Layer 9:你刚刚输入的那句话
很多人没意识到一件事:你说的“帮我查资料”“整理日报”“跟进客户”,在整个输入里只占最后一小部分。真正决定它怎么理解、怎么执行、怎么输出风格的,是前面八层内容长期累积的结果。
这解释了为什么同一个模型、同一句话,在不同 agent、不同配置、不同历史上下文下,反应会完全不同。也解释了为什么你一旦开始认真调教,时间往往会花在配置文件、记忆管理、prompt 调优、技能编排上,而不是单次对话。
九层架构不是玄学,它是工程现实。你越早理解这件事,越少会对“怎么它有时候突然变傻了”感到惊讶。

二,单 Gateway 多 Agent:不是多开几个 bot,而是操作系统级协作
余温那篇《我用 OpenClaw 搭了一套 5 角色 AI 协作操作系统》,很多人会看成“多开几个 bot 各干各的”。可他实际搭建的是另一套结构:
- 一个 Gateway 统一管理所有通道与路由
- 五个 Agent 各自独立人格、记忆、工作区
- 通道级别隔离,私聊不串、群聊不乱
- 规则驱动协作,不是自由群聊
- 双通道运行(Discord + Telegram),可以互相切换
这套架构的价值不在“多”,而在“可控”。
每个 Agent 清楚自己能干什么、不能干什么。系统清楚遇到什么情况该找哪个 Agent。协作不是靠“大家聊一聊”,而是靠预定义的规则和路由。
当你开始认真搭多 Agent 协作,你就已经从“玩一个 bot”进到了“设计一个小系统”。
三,Workspace 文件体系:每个 Agent 的独立办公室
每个 Agent 有自己独立的工作区,里面至少会包含:
- IDENTITY.md:它是谁
- SOUL.md:它的人格、优先级、行为准则
- USER.md:你是谁,你希望它怎么对待你
- MEMORY.md 或 memory/:它的长期记忆
- HEARTBEAT.md:它的巡检清单
- AGENTS.md 或相关配置:它能调的其他 agent
- skills/:它能用的技能
这些文件不是装饰。它们是 agent 的“大脑配置”。你每改一行,它的行为可能就会偏移一点点。长期使用的话,你会花大量时间在这套文件体系上做微调。
很多人第一次装完 OpenClaw,会忽略这一层。可一旦你开始认真用,你会发现,这套文件体系才是你和 agent 真正对话的地方。
这套系统的边界和风险在哪里
OpenClaw 的诱惑力很强,因为它能干的事情很多。可从安全和风险角度看,你最好在一开始就搞清楚几条边界。
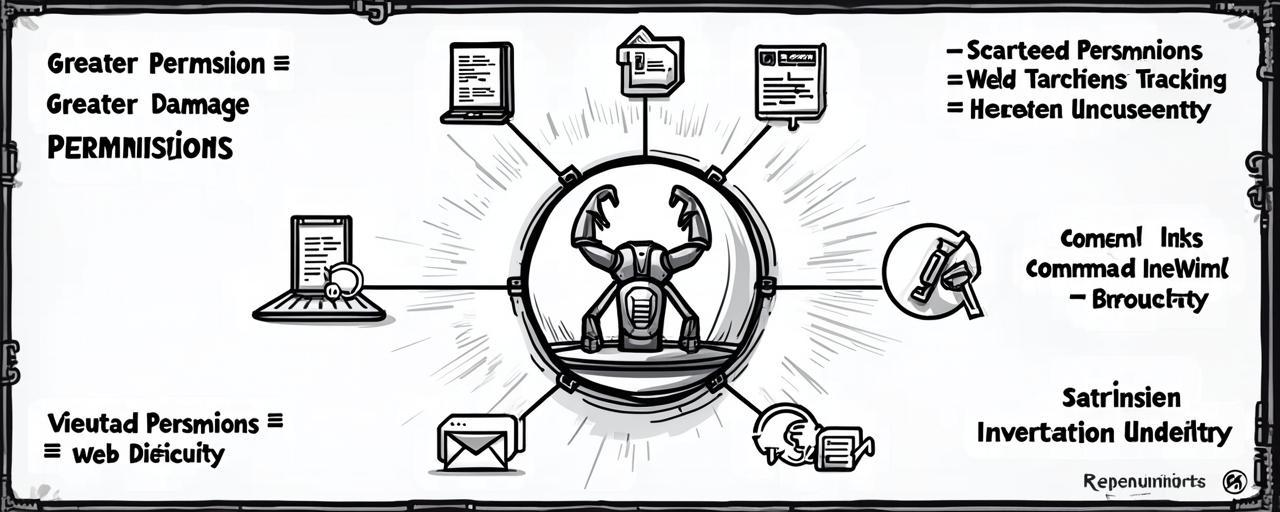
一,权限边界:能碰不等于该碰
目录里有不少文章提到,OpenClaw 可以读写文件、执行命令、操作浏览器、调用第三方 API、发邮件、发消息、改代码、改配置。这些能力单个看都很美,合在一起就是一个需要严肃对待的权限集合。
很多人第一次玩,会觉得“把权限开大点,它就更自由”。可问题出在另一面:
- 权限越大,它一旦出错能造成的破坏就越大
- 权限越散,你就越难追踪哪个动作到底谁干的
- 权限越模糊,你就越难判断什么时候该干预
更现实一点的策略是:
- 高风险操作(删库、删文件、改生产配置、发公开内容)默认人工确认
- 不同环境用不同权限等级(开发、测试、生产分开)
- 危险工具单独隔离,不直接接主通道
- 技能一条条验证,不要一口气装一堆网红包
二,自治边界:能自治不等于该长期自治
那篇《烧了二十亿 token 之后》提到的几个场景很值得玩味。
第一个场景,他希望 OpenClaw 自己完成飞书文档同步功能。结果系统一通操作,代码仓库多了十几坨不敢看的 diff,链接还是 404。
第二个场景,多 agent 在群里深夜狂刷屏,最后只能手动全清。
这些场景的共同点很简单:自治一旦没有边界,很容易跑偏。
更稳的做法是:
- 自治只适用于规则明确、风险可控、失败可回滚的环节
- 任何涉及外部系统改写、公开发布、高权限调用的动作,默认有人工确认
- 多 agent 协作先在隔离环境跑,验证稳定再上主通道
- 一旦系统表现异常,立刻降级人工介入

三,通道边界:连得越多,追踪成本越高
OpenClaw 支持 Telegram、WhatsApp、Discord、Slack、飞书等多种通道。很多人会觉得“都连上更方便”。可问题在于,通道越多,你就越难回答“它刚才到底干了什么”。
更实际的策略是:
- 先选一个你最常用的主通道
- 确保你能在那个通道里看到完整日志和操作痕迹
- 其他通道要么不连高风险动作,要么单独隔离
- 一旦发现异常,先断开通道,再查问题
四,记忆和上下文边界:记得越多,越容易混乱
长期记忆是 OpenClaw 的一大卖点。它确实能跨会话记住你的偏好、习惯、项目状态。可记忆越多,上下文管理就越复杂。
几个常见问题:
- 不同项目混在一起,agent 开始“串戏”
- 重要信息被大量无关上下文冲淡
- 历史决策被错误继承,导致一错再错
- 上下文膨胀导致 token 消耗失控、响应变慢
更稳的做法是:
- 不同项目用不同 agent 或不同工作区
- 记忆分层,区分项目级、任务级、偏好级
- 定期清理无价值的历史记录
- 重要配置仍然用显式文件,而不是只依赖对话历史
长期维护成本往往被前期文章低估
OpenClaw 的安装成本,很多文章已经讲得很清楚。可长期维护成本,往往被淡化。如果你真打算长期养,最好提前知道这些事。
一,模型成本比你想的更复杂
很多人第一次算账,会只看“每次对话多少钱”。可真实成本结构往往更复杂:
- 不同任务用不同模型,简单任务用便宜的,复杂任务用贵的
- 长上下文任务 token 消耗会非常快
- 定时任务、cron、长时运行,每天可能在不经意间烧掉不少钱
- 多 agent 协作会在后台默默调模型,你未必能第一时间感知
目录里 Star 那篇长文提到“分层模型”和“API 聚合路由”,就是在解决这个问题。他会把简单任务交给便宜模型,只把真正难的判断交给强模型。这比“全程用最强模型”省钱太多。
二,维护和调试成本比你想的更高
OpenClaw 不是一个“装完就不管”的工具。你真正用起来,会发现很多时间花在:
- 看日志,找 bug
- 调 prompt,调配置,调记忆结构
- 处理 token 超限、上下文溢出、格式错误
- 解决模型升级、API 变动、技能失效
- 处理通道风控、限流、登录态失效
- 清理冗余记忆、无价值历史、重复配置
很多人觉得这些是“一次性麻烦”。可长期看,这套系统像一台需要定期保养的机器。你越依赖它,越需要有人持续维护。
三,技能和依赖生态比你想的更脆弱
OpenClaw 的强大很大程度来自技能生态。可技能本质上是社区贡献的第三方代码。
几个现实问题:
- 技能可能突然失效,作者不再维护
- 技能可能引入安全风险或后门
- 技能之间可能冲突,或依赖特定环境
- 技能升级可能破坏你原本稳定的配置
更稳的策略是:
- 只装真正用得上的技能
- 装前先看代码、看权限、看评价
- 技能先在隔离环境测试
- 定期清理无用技能
- 重要工作流尽量自己写 skill,而不是完全依赖社区
四,心智负担比你想的更重
很多人以为 OpenClaw 能“解放脑力”。可长期使用,你会发现它在另一个层面增加了心智负担:
- 你需要记住哪些 agent 负责什么
- 你需要记得哪些任务能全自治,哪些需要确认
- 你需要时刻注意权限边界,别在错误通道发高风险指令
- 你需要定期回顾记忆和配置,避免系统走偏
- 你需要监控日志和成本,确保系统在正常轨道
这些都不是难到无法解决的问题。它们更像是一种“系统维护税”。你越依赖这套系统,越需要有人持续交这笔税。
如果你真的打算长期养,最好怎么开始
看完这批文章后,我对 OpenClaw 的态度很明确:它是一个很强大的个人自动化外壳,值得认真用,不值得盲目迷信。
如果你真的打算长期用,我建议按下面这个顺序来。
第一步,先用最小权限跑通一个小任务
不要一上来就让它“帮我搞定整个业务流程”。先选一个规则清晰、风险可控、容易验证的小任务。比如:
- 每天早上发一条天气提醒
- 每周汇总一次邮件标题
- 每次你拍一张照片,让它写一段简短描述
这一步的目标不是炫技,而是建立信任回路。你需要先确认系统在简单任务上不疯、不乱、不跑偏,再考虑让它做更复杂的事。
第二步,把权限和边界想清楚再放大
一旦小任务跑通,你会很容易想“再开点权限,让它多干点”。这个时刻非常关键。
最好在这一步先问自己几个问题:
- 这个任务如果做错,代价有多大
- 这个任务如果失败,能不能立刻回滚
- 这个任务如果失控,我能不能立刻切断
高风险动作一律人工确认,低成本、可回滚的动作再考虑自治。
第三步,为每个角色建独立工作区,不要混着用
你如果打算做多 agent 协作,最好一开始就为每个角色建独立工作区。
- 一个负责内容整理
- 一个负责客户跟进
- 一个负责研究资料
- 一个负责代码审查
每个角色有自己的 IDENTITY、SOUL、MEMORY、skills。不要让一个 agent 什么都干,否则你的系统很快会变得不可追踪。
第四步,建立日志和监控习惯,不要等出事再查
OpenClaw 不是黑盒。它有日志、有状态、有可追溯的记录。你最好从一开始就养成定期查看的习惯:
- 这周它干了哪些高风险动作
- 哪些任务失败率异常高
- 哪些技能突然失效
- token 消耗有没有突然暴涨
这些动作花不了多少时间,能替你省下大量事后救火成本。
第五步,定期“体检”,不要等系统自己告诉你问题
就像人会需要体检,系统也一样。你最好每隔一段时间做一次完整检查:
- 配置文件有没有冗余或冲突
- 记忆结构有没有混成一团
- 技能列表有没有过多无用项
- 权限设置有没有过宽或过时的部分
- 日志里有没有反复出现的小错误
系统不会主动告诉你“我有点不对劲”。它通常会在出大事的那一刻才会让你意识到问题早就存在。
我对 OpenClaw 长期价值的最终判断
看完整个目录后,我对 OpenClaw 的判断越来越清晰。
它不是神话。
它也不是骗术。
它是一个工程现实。
在工程现实里,任何工具都有代价,都有边界,都需要维护。OpenClaw 的特殊之处在于,它把很多以前分散在脚本、自动化工具、浏览器扩展、定时任务、提醒系统里的能力,重新打包成了一个更统一、更可编排、更易扩展的外壳。
这个外壳很有价值。
它尤其适合那些愿意自己设计工作流、愿意长期打磨配置、愿意在自动化和人工确认之间找平衡的人。
它不太适合那些希望“一句话甩手”的人。
也不太适合那些愿意把所有权限、所有判断、所有执行都外包给系统的人。
更不适合那些完全不想理解系统,只想享受红利的人。
OpenClaw 最值得用的地方,不在于它像人,而在于它能帮你把重复、流程化、规则明确的部分吃掉,把你从机械劳动里解放出来,让你把精力花在真正需要判断的地方。
当你理解了这一点,你就不会再被“全自动 AI 员工”“睡后自动赚钱”这些话带偏。
你会更在意:
- 这个工作流是不是稳
- 这个流程是不是可验证
- 这个系统是不是可维护
- 这个成本是不是可承受
这些事没那么性感。
可它们才决定了一个系统能不能真正活过第一波兴奋期。
本文主要参考材料
- huangserva:呕心沥血肝出来的,奉献给你们的龙虾了——OpenClaw Agent System Prompt 架构详解(9 层)
- 余温:我用 OpenClaw 搭了一套 5 角色 AI 协作操作系统
- Star@Day1Global Podcast:OpenClaw 终极指南
- OneHopeA9:OpenClaw:主人,我也想玩 app
- Jason Zhu:OpenClaw 完全指南
- 烧了二十亿 token 之后,我终于承认 openclaw 真的没用
- Roland 的思考日记:用 OpenClaw 搭了个自动化系统
- Kevin Ma:MaxClaw 详细深度实测与问题解答







评论前必须登录!
立即登录 注册