写在前面
如果你这两个月已经明显感觉到 Claude Code 有点“不对劲”,那你可能不是错觉。
这次把争议推到台面上的,不是一条零散吐槽,也不是某个博主的主观感受,而是一份来自真实工程团队的量化分析:基于 6852 份 Claude Code 会话日志、17871 个 thinking 块、234760 次工具调用和 18000 多条用户提示词,结论指向同一件事——Claude Code 从 2 月开始出现了系统性退化。
最刺眼的数字是:思考深度中位值下降了 67%,后续阶段甚至接近 75%。 对写代码的人来说,这不是“回答变短了”这么简单,而是你会直接感受到:它更急、更糙、更容易跳步骤,也更容易在复杂工程任务里把事情做歪。
更要命的是,这类变化不会只影响体验,它会影响你对 AI 编程工具的信任方式。以前你担心的是“它能不能做”,现在很多团队开始担心的是:它什么时候会突然不靠谱。
当 AI 编程开始变急躁,真正出问题的不是输出长度
这篇原文最值得看的地方,不是情绪,而是它把“退化”这件事拆成了可以量化的行为变化。
AMD AI 团队负责人 Stella Laurenzo 直接在 GitHub 官方仓库发 Issue,标题级别的判断非常重:Claude 已经无法再被信任去执行复杂工程任务。 这不是一句气话,背后是她们团队持续积累的项目日志分析。
Hacker News 上这条讨论很快发酵,拿到了 975 点支持和 548 条评论。很多开发者的感受也高度一致:以前它更像一个聪明的结对编程伙伴,现在更像一个特别热情、但总是抢着把事情做坏的实习生。
这里真正值得警惕的,不是某个回答偶尔翻车,而是工作流层面的变化:
- 本来应该先读文件、再理解上下文、再动手改代码
- 现在更容易出现“还没看清就先改”“为了尽快结束任务而给临时方案”
- 当任务稍微复杂一点,模型会更频繁地推诿、提前终止,或者要求额外确认
对工程团队来说,这种退化的破坏性远大于“偶尔答错一题”。因为复杂项目最怕的不是不会做,而是看起来在做,实际上持续制造返工。
数据实锤:思考深度、读改比、用户中断率,全都在往坏的方向走
原文里最硬的一部分,是它没有停留在“感觉变笨了”,而是拿出了一条很清晰的时间线。
1)思考深度明显缩水
根据日志分析:
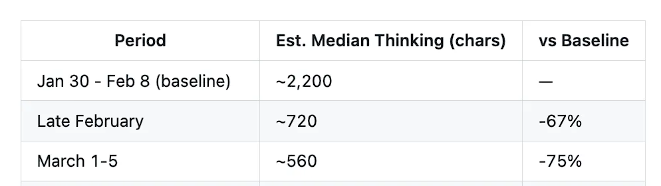
- 1 月 30 日到 2 月 8 日:属于相对稳定的“优质期”,思考深度中位值约 2200 字符
- 2 月下旬:掉到约 720 字符,降幅 67%
- 3 月初:进一步掉到约 560 字符,相对优质期降幅接近 75%
如果你把 thinking 看成模型在真正下手前做的“脑内草稿”,那这个变化的含义就很直接了:它不是变懒了一点,而是前置推理预算被明显压缩了。
2)“先研究再修改”的习惯开始消失
更关键的是读改比,也就是每次编辑前会先读取多少文件。
- 在优质期,读改比达到 6.6
- 到 3 月 8 日后的退化期,掉到 2.0
这意味着研究投入下降了大约 70%。放在实际编码场景里,差别就是:
- 以前更像一个会先通读上下文、确认依赖、再动刀的工程师
- 后来更像一个只扫两眼就开始下手改的助手
报告里还提到一个特别扎眼的现象:退化期里,每三次代码修改就有一次是在没读目标文件的前提下直接动手。
这种行为会带来的问题很具体:
- 代码插到了错误位置
- 注释和语义关系断掉
- 局部看似改完了,整体逻辑却被破坏
如果你最近经常碰到“它改得很快,但你得花更多时间收残局”,大概率就是这一层的问题。
3)坏行为开始从偶发变成高频
团队还用终止钩子脚本去抓“推诿责任、提前终止、请求许可”等异常行为。
结果很夸张:
- 3 月 8 日之前:0 次触发
- 之后 17 天:173 次触发
- 平均下来,每天 10 次
与此同时:
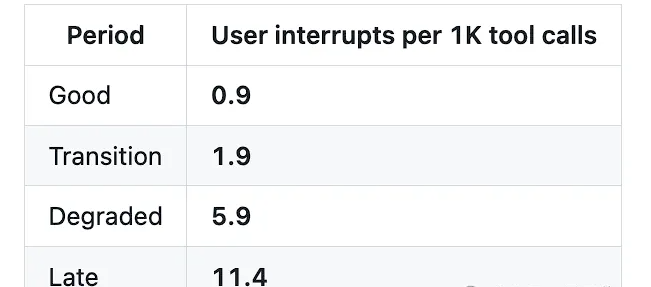
- 用户提示词里的负面情绪占比,从 5.8% 升到 9.8%,涨幅 68%
- 用户强行中断模型的频率,相比优质期飙升 12 倍
这些指标放在一起看,说明退化不是“输出风格变了”,而是人机协作关系本身变差了。
最敏感的争议点,不只是退化,而是退化后来被“看不见”了
整件事最容易刺痛开发者的,其实不是能力变弱,而是能力变弱之后,外部越来越难观察到它到底还在想什么。
报告把一个叫 redact-thinking-2026-02-12 的功能拎了出来。按时间线看:
- 3 月 5 日 开始灰度上线,覆盖 1.5%
- 3 月 10 日到 11 日 已经覆盖 99%+
- 3 月 12 日 起全量生效
它的作用,是把 API 响应里的思考内容剥离掉,让用户无法直接从外部看到模型的推理过程。
作者的判断很尖锐:3 月初上线的隐藏功能,并不是制造了退化,而是让退化变得不那么容易被用户察觉。
更值得注意的是,日志显示退化其实在 2 月中旬就已经开始了,时间上又和另外两个节点高度重叠:
- 2 月 9 日:Opus 4.6 上线,引入自适应思考(adaptive thinking)
- 3 月 3 日:默认
effort从高降到中等(Medium)
报告还发现了一个很微妙的规律:思考深度会随时段波动。
- 太平洋时间 17:00 是最差时段,中位估算仅 423 字符
- 19:00 是第二差时段,仅 373 字符
这不像固定预算,更像是会随着平台负载变化而动态收缩的推理资源分配。对开发者来说,这意味着同一个 prompt、同一个项目,在不同时间跑出来的“认真程度”都可能不一样。
Anthropic 怎么回应?重点不在“有没有解释”,而在解释够不够
Claude Code 团队成员 Boris 很快给出了回应,核心意思大概有两层。
第一层是:thinking 隐藏只是 UI 层改动,不影响模型实际推理。 用户如果想恢复显示,可以在 settings.json 里开启:
{
"showThinkingSummaries": true
}
第二层是:他承认团队在 2 月确实做了两项实质性调整:
- 引入 adaptive thinking
- 把默认
effort从高改成中等
官方给出的临时恢复方式也很直接:
- 在 Claude Code 里手动执行
/effort high或/effort max - 通过环境变量关闭自适应思考
export CLAUDE_CODE_DISABLE_ADAPTIVE_THINKING=1
但问题在于,社区并不觉得这足以解释全部现象。
因为不少开发者反馈:即便把 effort 拉高,模型那种“急着收工”“先给个能交差的答案”的倾向还是变明显了。 也就是说,争议已经不只是默认设置被调低,而是很多人怀疑底层行为模式本身发生了变化。
这也是为什么这次讨论会发酵得这么快。开发者最难接受的,不是模型偶尔退步,而是:
- 默认能力被改了,但很多人事先并不知道
- 你以为自己还在用原来那个“很会深挖问题”的 Claude
- 实际拿到的,却是一个更强调速度和完结感的版本
真正让团队顶不住的,往往不是质量下降,而是成本失控
如果说前面的数据还只是“体验问题”,那成本部分就已经是业务问题了。
报告给出的对比非常夸张:
- 2 月到 3 月,用户提示词数量几乎持平:5608 vs 5701
- 但 API 请求量暴涨 80 倍
- 总输入 token 增长 170 倍
- 输出 token 增长 64 倍
- 按 Bedrock Opus 定价估算,月度成本从 345 美元 飙升到 42121 美元,涨幅 122 倍
这背后不是单一原因。
一方面,团队确实扩容了并发 Agent 数量;但另一方面,退化带来的无效循环、频繁中断和重试,又把每单位有效工作需要消耗的 API 请求额外放大了 8 到 16 倍。
这就很现实了:
- 人没少干多少活
- 任务目标也没变复杂多少
- 但为了把活做完,你得多付出成倍的 token 和监督成本
最后团队只能关停整个 Agent 集群,退回到单会话、人工盯着的模式。这其实特别说明问题:当一个编程 Agent 需要你越来越频繁地盯梢,它就不再像“队友”,而更像“高成本实习生”。

这件事对开发者真正的提醒,不是“换不换工具”,而是怎么重新理解 AI 编程
很多人看完这类新闻,第一反应会是:那是不是该转 Codex、Gemini CLI、Qwen 或别的工具?
这当然是一种选择,但更重要的收获其实有三点。
1)别再把 AI 编程能力当成稳定常量
模型不是你本地安装的一个固定版本工具。它背后会持续改默认参数、调策略、重分配预算、改显示逻辑。
也就是说,你今天熟悉的“那个 Claude Code”,下个月可能就不是同一个工作伙伴了。
2)复杂任务一定要看工作流指标,不只看 Demo 观感
真正决定工具值不值得押注的,不是它某次 demo 写得多惊艳,而是这些更工程化的指标:
- 读改比是否稳定
- 是否愿意先研究再修改
- 长任务里会不会越来越急躁
- 出错后是修问题,还是开始找借口
- 你为监督它额外付出的时间有没有越来越多
3)多准备一条备用通道,已经不是“可选项”了
当主力模型行为开始波动,团队需要的不是情绪,而是冗余。
你可以继续把 Claude Code 当主力,但最好也准备好其他路线,比如 Codex、Gemini CLI,或者统一的 API 接入方式。这样一旦某个工具的默认行为发生变化,你至少不会整个工作流直接断掉。
Claude Code 到底是什么?为什么它一变,开发者反应会这么大?
如果你不是一直深度使用这类工具,可能会疑惑:不就是一个 AI 编程助手吗,为什么这次社区反应这么激烈?
关键在于,Claude Code 本来就不是普通补全插件。
它更像一个在终端里工作的代码 Agent,能做的事情包括:
- 读写项目文件
- 执行命令
- 搜索代码和分析依赖
- 跨文件修改和重构
- 结合配置、日志、测试结果继续迭代
也正因为它做的是“接近工程执行层”的工作,开发者才会对它的思考深度、任务边界感、行动稳定性格外敏感。你让一个聊天机器人答错一题,影响没那么大;但你让一个能动你项目的 Agent 变得更草率,后果就完全不是一个量级了。
官方订阅通常跟 Claude 体系绑定,具体套餐和价格以 Anthropic 当时页面为准。对国内用户来说,真正麻烦的往往不是功能本身,而是支付方式、网络环境和账号稳定性。如果你嫌这些环节太折腾,想找个更省事的渠道,可以看看 Code80,真实订阅帐号转 API,换个 endpoint 就能直接用,体验会更接近官方那套工作流。详情可以到官网了解:code.ai80.vip
常见问题
Q1:这次争议等于 Claude Code 彻底不能用了?
不等于。更准确地说,是很多重度用户发现它在复杂工程任务上的稳定性和深度出现了明显波动。轻量任务、常规改写、小范围文件处理,未必就完全不可用。
Q2:/effort high 或 /effort max 还有没有意义?
有意义,至少它仍然是官方认可的直接干预手段之一。但从社区反馈看,光把 effort 拉高,并不能完全恢复过去那种稳定的“先研究再动手”的状态。
Q3:CLAUDE_CODE_DISABLE_ADAPTIVE_THINKING=1 是不是建议所有人都开?
如果你明显遇到思考波动、长任务变糙、行为变急的问题,可以试试。但它更适合有明确工程场景、能对比前后结果的人,不太适合盲目一刀切。
Q4:这次最值得关注的指标是什么?
如果只看一个,我会选读改比。因为它直接反映了模型是不是还愿意在修改前花时间理解上下文。对复杂项目来说,这个指标几乎决定了返工率。
Q5:为什么很多人开始提 Codex 或其他替代方案?
因为当一个 Agent 的默认行为开始不稳定,团队自然会寻找第二选择。这里未必是“谁绝对更强”,而是谁在当前阶段更稳、更可控、更适合自己的工作流。
Q6:国内用户如果想更方便地接入 Claude Code,有没有省事一点的方式?
有,国内用户可以通过 Code80 更方便地使用。








评论前必须登录!
立即登录 注册