写在前面
这篇源码拆解最震撼的地方,不是“模型多强”,而是一个现实:真正让 AI Coding Agent 稳定跑在生产环境里的,主要不是模型本身,而是外围 Harness。
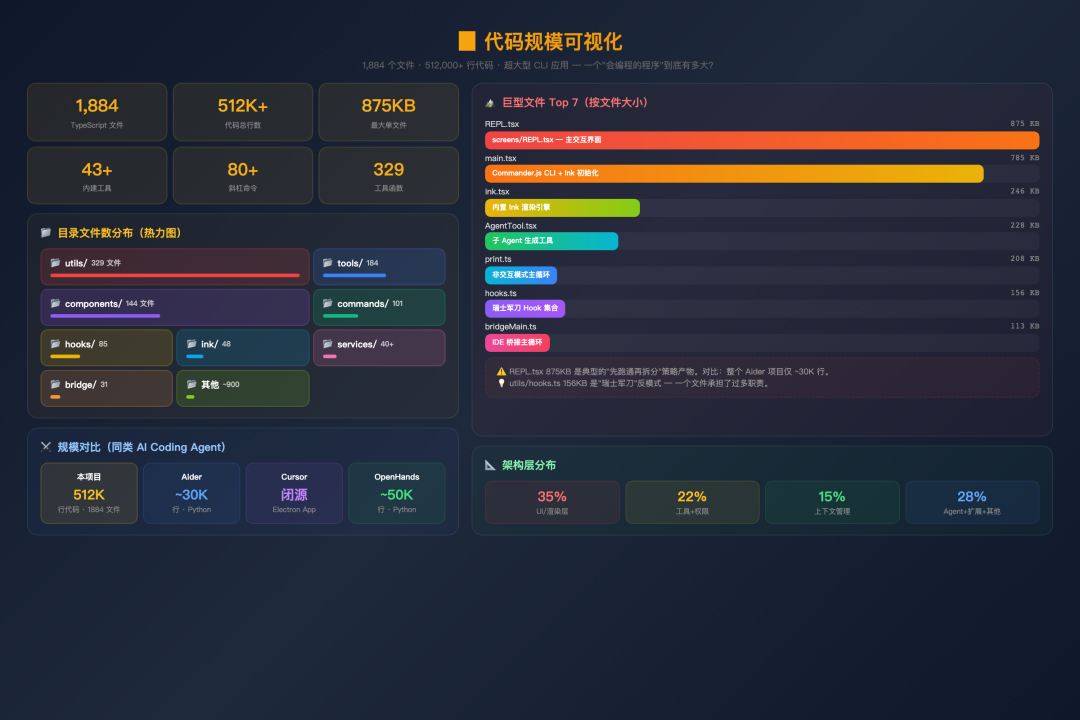
这份工业级项目给出的体量很硬:约 1,900 个文件、512,000+ 行代码,核心是一个 TypeScript CLI Agent,但完整做出了多 Agent、权限系统、流式执行、上下文压缩、任务编排、终端交互和插件生态。
你可能会关心:
– 为什么它把大量工程精力放在 Harness,而不是“再换一个更强模型”?
– 50 万行级别的 CLI 是怎么把冷启动和交互延迟压下来的?
– 这些设计里,哪些是你自己的 Agent 项目今天就能抄作业的?
先看结论:AI Agent 的竞争,已经进入 Harness 阶段
这份代码释放了一个很明确的信号:
- Prompt 重要,但不再是唯一差异点
- Context 很关键,但也只是中层能力
- 真正拉开生产差距的是 Harness Engineering:约束、恢复、隔离、可观测、可扩展
当项目复杂到 50 万行时,系统是否能持续稳定迭代,取决于你怎么组织 Agent 的“运行环境”,而不是只看模型参数。
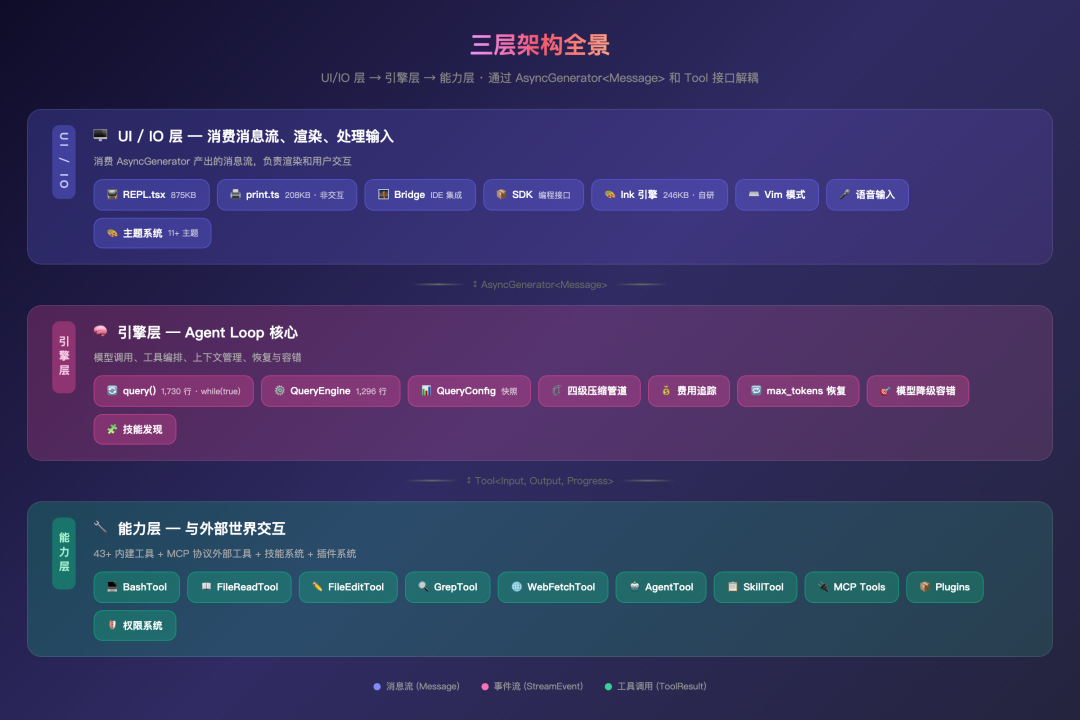
Part 1:项目全景与技术选型(为什么是这套栈)
先看规模数据:
| 指标 | 数据 |
|---|---|
| TypeScript 文件 | ~1,884 个 |
| 代码总行数 | 512,000+ |
| 最大单文件 | screens/REPL.tsx 约 875KB |
| 工具实现 | 43+ |
| 斜杠命令 | 80+ |
技术选型的核心思路不是“追热度”,而是“追瓶颈”:
– 运行时选 Bun(启动速度、构建与 DCE)
– TypeScript strict(超大工程可维护性)
– React + Ink 做终端 UI(复杂交互可组合)
– Zod 做 schema 校验(工具输入和配置兜底)
– MCP + LSP 做外部工具与代码智能拓展
Part 2:启动流程(怎么把 CLI 做到“秒开”)
它的启动链是分层设计:
cli.tsx先走 Fast Path(如--version直接返回)main.tsx在模块加载阶段并行预取(MDM、Keychain 等)init.ts做全局单例初始化(memoize)setup.ts做会话级准备
关键不是某个黑科技,而是多个“工程小决策”叠加:
– 能不加载就不加载
– 能并行就并行
– 重模块延迟导入
– feature gate 配合构建期 dead code elimination
Part 3:工具系统(Fail-Closed 不是口号,是默认配置)
这套工具系统最值得学的是“保守默认值”:
isConcurrencySafe默认 false(先当作不安全)isReadOnly默认 false(先当作会写入)- 工具需显式声明能力,再逐步放开
同时它把工具注册做成了单一出口 + 条件加载,并区分编译期开关与运行期开关。这样做的好处是:
– 外部构建天然剥离内部能力
– 工具列表稳定可控
– Prompt cache 更稳定
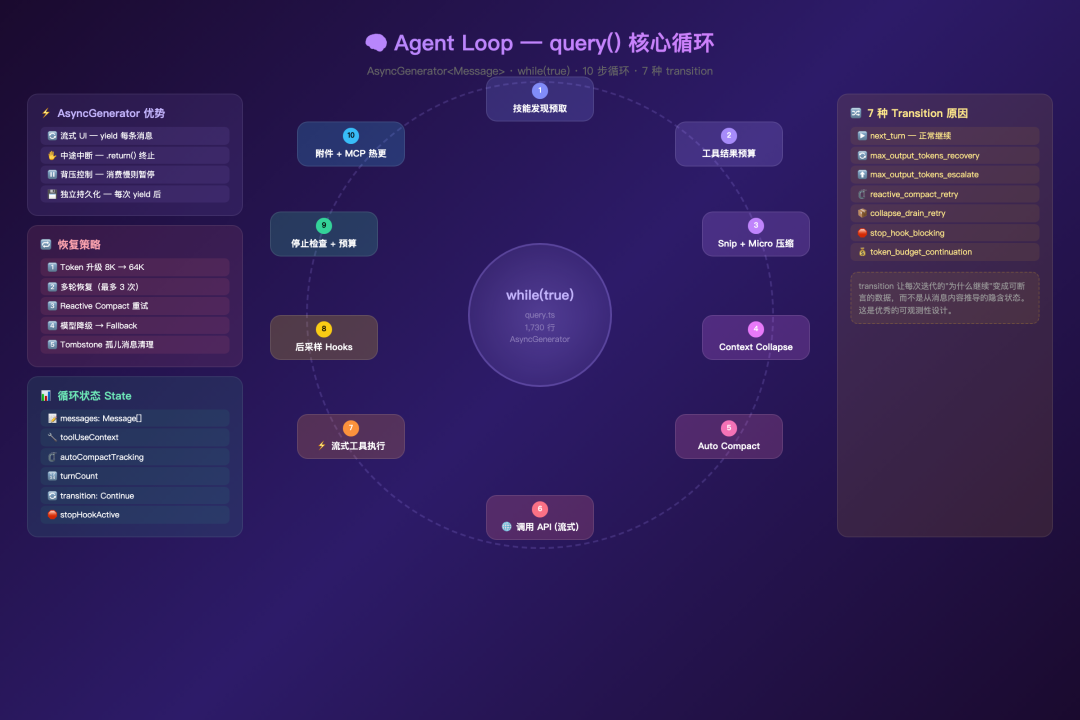
Part 4:查询引擎(Agent Loop 真正的核心)
query.ts + QueryEngine.ts 这组设计很像“工业控制循环”:
- 主循环用
AsyncGenerator驱动流式输出 - 工具执行支持并发安全判定
- 有完整的 max tokens 恢复机制
- 关键配置做快照,避免运行中漂移
最关键的是它做了四级压缩管道:
– Snip Compact
– Micro Compact
– Context Collapse
– Auto Compact
这意味着会话越长,系统不是“撑爆”,而是“渐进降级”。
Part 5:多 Agent 编排与任务系统(不是“能并行”,而是“可治理地并行”)
它不是简单加了个 Agent tool,而是把任务类型、状态、取消、通信都系统化了。
典型能力包括:
– 子 Agent 生成
– 团队协作(teammate)
– 远程 Agent
– 任务 ID 分型与生命周期管理
– 协调器模式(控制面/执行面分离)
这类设计的价值是:项目变大后,系统不会因为“多开几个 Agent”就失控。

Part 6:终端 UI 工程(把 CLI 当“应用”做)
这个项目在 TUI 上是重投入路线:
– 自带 Ink 渲染引擎而不是只依赖 npm 包
– 大量组件与 hooks
– Vim 模式、键绑定系统、桥接系统
– 超大 REPL 交互层
从工程角度看,这是一种明确取舍:维护成本更高,但换来渲染与交互的完全控制权。
Part 7:Harness Engineering 方法论(2026 最值得关注的工程范式)
把这份项目抽象成方法论,大致就是六个支柱:
- 上下文架构(注入与压缩)
- 架构约束(权限与边界)
- 自验证循环(恢复与重试)
- 上下文隔离(多 Agent 防污染)
- 熵治理(自动整理记忆/状态)
- 可拆卸性(模块化与替换能力)
这也解释了为什么现在很多团队都在谈“Model + Harness”:同一个模型,Harness 不同,最终可用性差异会非常大。

Part 8:彩蛋系统(工程团队文化也写进了代码)
这篇源码分析里最“反差萌”的部分,就是那些隐藏彩蛋:
– Buddy 伴侣精灵
– AutoDream 梦境系统
– thinkback 年度回顾
– btw 旁路提问
看起来像“好玩功能”,但背后其实也有工程逻辑:
– 记忆巩固
– 会话体验连贯性
– 用户长期留存
Claude Code 是什么?能做什么?
如果你刚接触这类工具,可以把 Claude Code 理解成“命令行里的 AI 编程 Agent”,而不是普通补全插件。它更像能独立执行任务的搭档,典型能力包括:
- 读写项目文件、跨文件改动
- 跑 shell 命令和测试
- 检查 git 状态并协助提交流程
- 通过 Skills / hooks 接入团队工作流
官方订阅走 Claude.ai:Pro 计划约 $20/月,Max 计划约 $100/月(含更多 Claude Code 额度)。
不过说实话,官方订阅对国内用户不太友好——需要海外信用卡,网络环境也得折腾。如果嫌麻烦想找个更省事的渠道,可以看看 Code80,真实订阅帐号转 API,换个 endpoint 就能直接用,体验跟官方一样。详情可以到官网了解:code.ai80.vip
常见问题
Q:这份 50 万行源码最值得普通团队借鉴的点是什么?
A:优先借鉴三件事:Fail-Closed 工具权限默认值、四级上下文压缩管道、可恢复的查询循环状态机。这三项直接提升“长会话可用性”。
Q:做一个 AI Coding Agent,先堆模型还是先搭 Harness?
A:模型要够用,但工程优先级应尽早转向 Harness。模型决定上限,Harness 决定你能不能稳定地接近上限。
Q:为什么这类项目会出现超大文件(比如 REPL 超大单文件)?
A:通常是高压迭代下的结果:先保证功能打通,再逐步模块化。短期快,长期会积累认知与维护成本。
Q:多 Agent 一定比单 Agent 好吗?
A:不一定。多 Agent 更强,但前提是你有任务分发、上下文隔离、取消/重试和结果合并机制,否则很容易放大混乱。
Q:国内怎么更方便用上 Claude Code?
A:国内用户可以通过 Code80 更方便地使用。









评论前必须登录!
立即登录 注册