
写在前面
最近一直在关注大模型,Llama 4、Gemini 2.5 Pro、DeepSeek 新版本都在抢时间窗,而 OpenAI 终于把最受关注的一张牌摊开了——GPT-6。
这次不是“常规小升级”。多方消息把它描述成 OpenAI 内部的关键战役:更大的上下文、更激进的架构、几乎不涨价的定价策略,目标非常直接——把开发者和企业市场的注意力重新拉回自己身上。
真正值得你关心的问题其实就三个:GPT-6 到底强在哪?它面对的竞争盘面有多凶?如果你是开发者,现在该怎么选工具、怎么下注?
不是参数竞赛了:2026 年 AI 的胜负手正在变化
这轮竞争的核心,已经从“谁先发布”转向“谁能在真实工作流里形成体验代差”。
从公开信息看,GPT-6 被反复强调的不是单个 benchmark,而是三件事:
- 代码、推理、智能体任务整体性能据称较 GPT-5.4 提升 40%+
- 上下文窗口到 200 万 Token,长任务处理能力继续上探
- 在高性能前提下维持接近上一代的价格带
这背后反映的是一个很现实的行业变化:企业和开发者越来越看重“单位成本下的可交付能力”,而不只是某次跑分。谁能在长上下文、工具调用、多模态输入、自动化执行这几件事上同时做到可用,谁就更容易拿走预算。
GPT-6 的核心信息,一次看全
1)发布时间与定位
OpenAI 官方确认 GPT-6 将在 4 月 14 日发布,预训练已在 3 月中旬完成。内部叙事里,它被贴上了“AGI 的最后一公里”这种高压标签,意味着这代模型承担的不只是技术升级,还有市场反攻任务。
2)性能与规模信号

已披露或被广泛引用的数据点包括:
- 性能:代码 / 推理 / 智能体任务提升 40%+
- 上下文:200 万 Token(约可处理 150 万字)
- 参数:5-6 万亿(MoE 架构,激活参数约 10%)
- 训练资源:约 10 万张 H100,投入约 20 亿美元
对开发者最直接的影响是:超长文档、跨仓库代码理解、复杂多步骤任务,理论上都更适合一次性在同一上下文里完成,不用频繁拆片喂给模型。
3)架构重点:Symphony
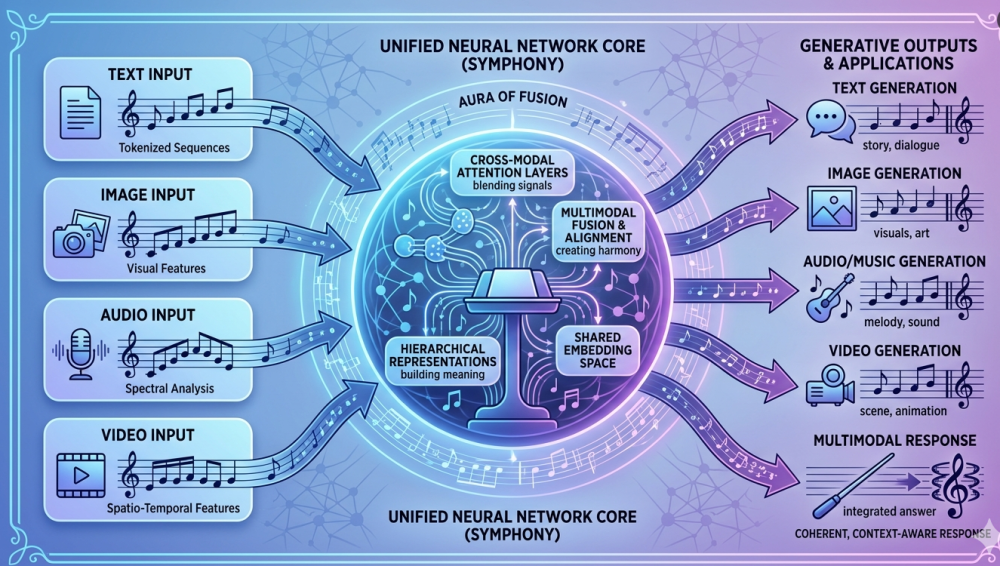
GPT-6 被重点宣传的是所谓 “Symphony” 架构,关键词有两个:
- 原生多模态统一:文本、图像、音频、视频在同一向量空间协作,而不是后接插件式拼装
- 双系统推理:System-1 快速生成 + System-2 多步校验,目标是提升复杂任务的稳定度
如果这套机制在实测里成立,它的价值不在“聊天更像人”,而在“处理复杂生产任务时,返工率更低”。
4)定价策略
官方披露的价格信号是:每百万 Token 输入 2.5 美元、输出 12 美元,基本贴着 GPT-5.4 的区间。
这意味着 OpenAI 在做一件很明确的事:用高规格能力配相对克制的价格,争夺企业迁移窗口。
对手并不弱:4 月是“群狼环伺”的一个月
Meta:Llama 4 系列
- 总参数规模达万亿级
- 官方基准成绩亮眼,但第三方评测对部分编码能力有争议
- 优势依然是开源可部署与生态渗透
Google:Gemini 2.5 Pro + Flash
- 持续强化推理和多模态
- 长上下文与低成本版本对文档处理场景很有吸引力
- 在企业决策者心智中占比提升明显
Anthropic:Claude 4 系列
- 编程相关能力和开发者口碑持续走高
- 企业侧份额增长与订阅增长数据表现强势
- 在“工程化可落地”维度上形成了很强竞争压力
DeepSeek:R2 / V4

- 继续强调 MoE 效率、训练成本和性价比
- 多模态与超长上下文预期拉满
- 国产算力与生态路线带来额外变量
结论很直接:GPT-6 发布不会是“新王登基”的终点,而是下一轮混战的起点。
OpenAI 要翻盘,关键看这三件事
一、原生多模态是否真的形成体验断层
如果多模态统一只是“能用”,不足以改变格局;但如果它能稳定支撑真实业务链路(图文视频混合输入 + 自动执行),就会直接改变工作流。
二、智能体整合是否超过当前头部编程工具体验
GPT-6 被描述为会把 ChatGPT、Codex、浏览器能力等整合为统一应用。问题不在功能列表,而在连贯性:从理解需求到落地改代码,是否能少切换、少断点、少返工。
三、价格策略能否触发企业级迁移
性能提升 + 价格稳定,本质是“用资本换市场份额”。如果上线后实际质量兑现,这个组合会非常有杀伤力。
对开发者来说,真正该调整的不是观点,而是工作方式
今天再讨论“要不要用 AI 写代码”已经没意义了,问题变成:
- 你是否把模型当成一次性问答工具,还是持续协作的工程代理
- 你是否在做可复用的 Agent 工作流(规划、执行、验证、回滚)
- 你是否能在多模型并行的时代,按任务类型选择最合适的能力
谁先完成这次工作方式迁移,谁就会在同样的人力下拿到更高交付密度。
Claude Code 是什么?能做什么?
如果你更关注“今天就能用起来的工程化 AI 编程”,Claude Code 是目前非常主流的一类 Agent 形态:
- 在命令行内读写项目文件、跨文件理解和修改
- 执行 shell 命令、跑测试、看 git 状态并继续修复
- 支持长链路任务,不只是补全几行代码
- 可以结合 Skills 与 hooks 接入团队工作流
官方订阅走 Claude.ai:Pro 计划 20 美元/月,Max 计划 100 美元/月(含更多 Claude Code 额度)。
不过说实话,官方订阅对国内用户不太友好——需要海外信用卡,网络环境也得折腾。如果嫌麻烦想找个更省事的渠道,可以看看 Code80,真实订阅帐号转 API,换个 endpoint 就能直接用,体验跟官方一样。详情可以到官网了解:code.ai80.vip
常见问题
Q1:GPT-6 这次最值得关注的点是什么?
A:不是单个跑分,而是“40%+ 任务表现提升 + 200 万 Token + 架构重构 + 价格控制”这组组合拳是否能在真实业务里成立。
Q2:200 万 Token 对开发者有什么实际意义?
A:长文档、跨模块代码库、复杂多轮上下文任务的处理上限更高,理论上能减少切片和反复补上下文的成本。
Q3:OpenAI 这次最难的挑战是什么?
A:不是发布会当天的声量,而是上线后在编程和企业场景里持续证明“稳定、可复现、可规模化”。
Q4:现在选模型该看什么指标?
A:优先看你的真实任务:代码质量、长任务稳定性、工具调用成功率、单位成本,而不是只看公开榜单。
Q5:国内怎么更方便用上 Claude Code?
A:国内用户可以通过 Code80 更方便地使用。









评论前必须登录!
立即登录 注册