写在前面
刚刚,Anthropic 发布了 Claude Opus 4.7。
这一版的核心升级,和前一天推出的 Routines 其实是同一条线上的事:让 AI 能跑更长、更复杂的任务,还能自己检查结果,尽量减少你盯着它的时间。
定价也没变,和上一代 4.6 一样,输入 5 美元、输出 25 美元,每百万 token。
如果把这次更新拆开看,它像是在补几个功能点;但连起来看,方向已经很明显了:Claude 不只是回答得更好,而是在朝着“更少依赖人类频繁介入”的方向继续推进。
先会自己检查,再把长任务接过去
Opus 4.7 这次补上的,不是什么很花哨的新概念,而是一个以前没那么突出的能力:在把结果交出来之前,先自己验证一遍。
发现问题,就先在内部修掉,再给答案。
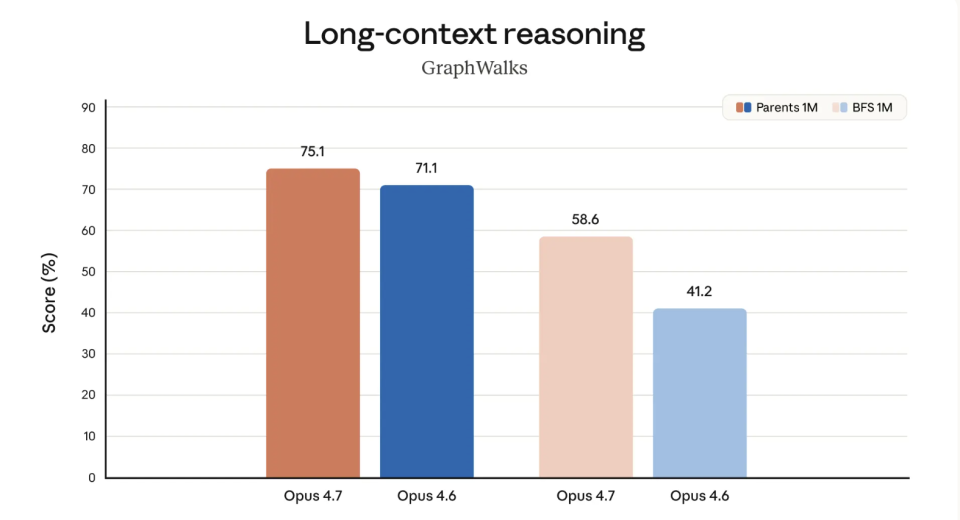
听起来像只是多了一步检查,但放到自主运行场景里,意义其实很大。过去让 Claude 连着跑几小时任务,最怕的不是慢,而是最后才发现中间某一步已经跑偏了。现在它开始能自己发现、自己纠正,人需要插手的节点又少了一层。
Rakuten 给出的数据很直接:用 Opus 4.7 跑生产任务,解决率提升了 3 倍,代码质量“提升了 10 个数量级以上”。
在多任务工作流上,Opus 4.7 相比 4.6 提升了 14%,工具调用出错率下降约三分之一,token 消耗也降低了。
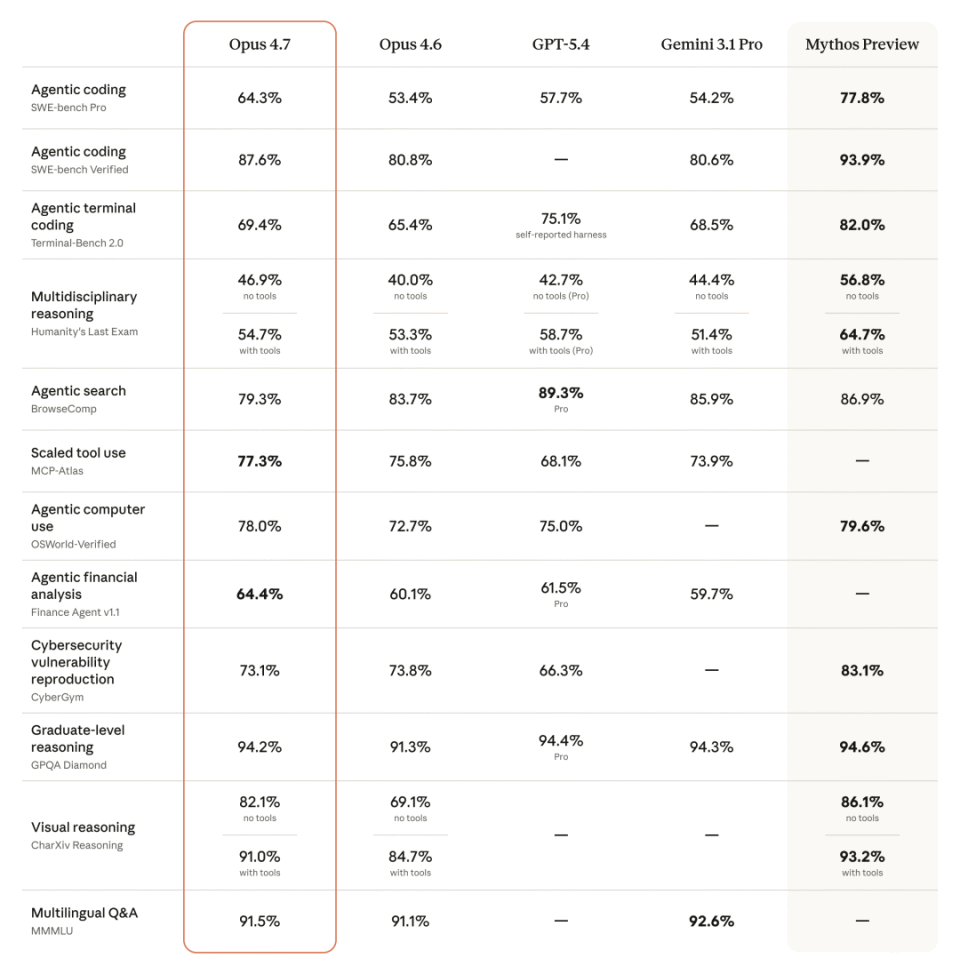
这一组变化放在一起,核心就一句话:更可靠,也更省钱。
视觉能力一下抬高了一个台阶
这次另一个很扎眼的点,是视觉能力。
Opus 4.7 现在支持最高 2576 像素长边的图像,约 375 万像素,分辨率是之前的 3 倍以上。像生成界面原型、做演示文稿、看化学结构、读技术图表这种任务,细节稍微糊一点都不行,这次算是把底子补厚了。
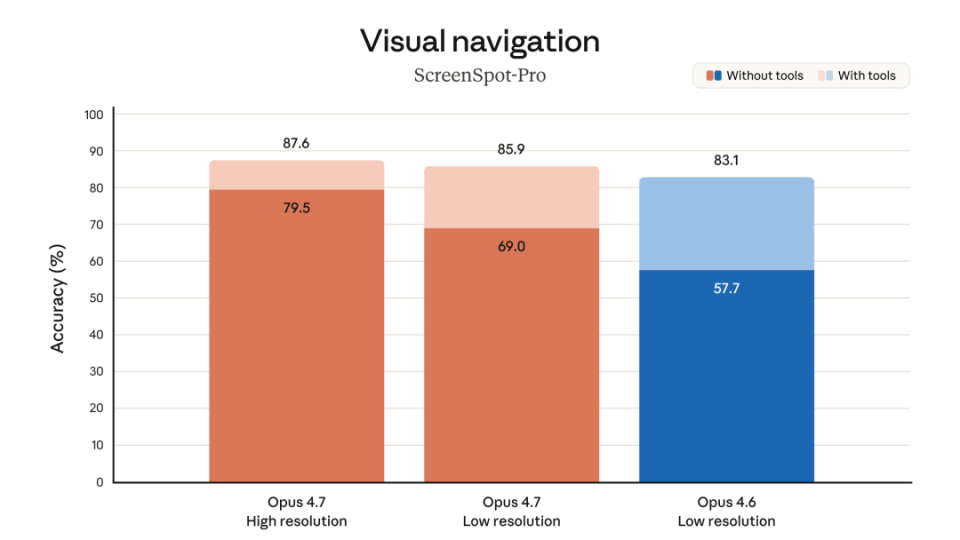
XBOW 给出的数据更夸张:在计算机视觉感知基准上,Opus 4.7 得分 98.5%,而 Opus 4.6 是 54.5%。
从 54.5% 直接跳到 98.5%,跨度已经不是小修小补了。XBOW 的评价也很直白:彻底解决了他们的主要痛点。
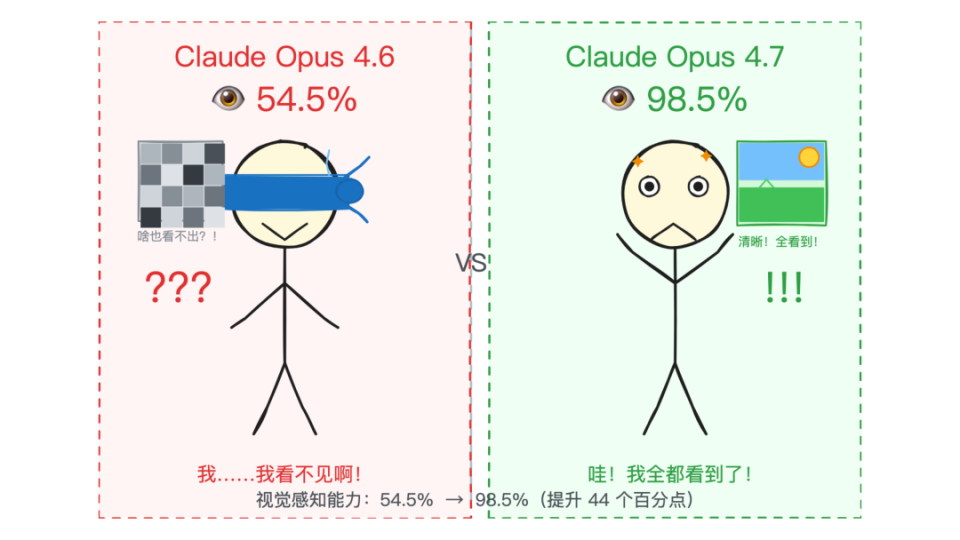
这件事为什么重要?因为 AI 一旦要接更长链路的任务,就不可能只处理纯文本。看截图、读 UI、理解图文混排文档,都会越来越常见。分辨率和视觉感知能力一旦上来,很多原来不够稳的任务才真正有了可用基础。
编程能力继续往上顶,Claude Code 也顺手补了一刀
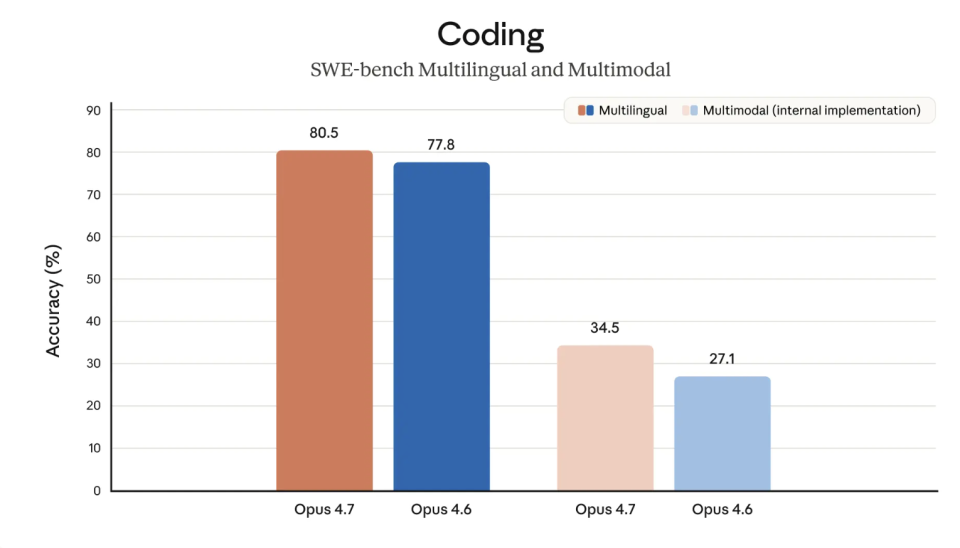
编程能力这一块,Opus 4.7 也继续往前推。
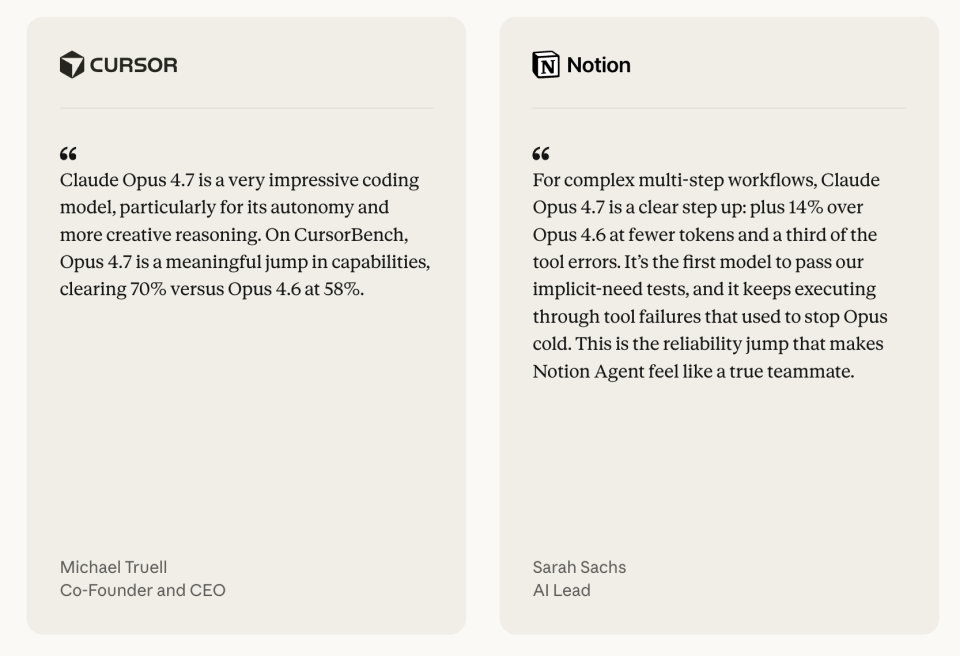
Cursor 在 CursorBench 上的数据是 70%,而 Opus 4.6 是 58%。
Notion 的反馈则是,整体性能提升 14%,工具调用出错率下降约三分之一,而且第一次通过了“隐性需求”测试项,也就是那些用户没明说、但模型应该理解到的要求。
CodeRabbit 用在代码审查上时,最复杂 PR 的召回率提升了 10% 以上,精准度基本没掉;Databricks 那边,文档推理错误减少了 21%。
到了 Claude Code 这一层,这次还新加了 /ultrareview 命令,专门跑一轮深度代码审查。

它会把所有改动完整读一遍,把一个认真 reviewer 会挑出来的问题尽量都找出来,包括 bug 和设计层面的隐患。你不用再单独开一个对话,也不用手动提醒它“帮我 review 一下”,直接一条命令跑完就行。
同时,Auto Mode 也向 Max 用户开放了。更长的任务,不会像以前那样频繁被打断。再和前面已经上线的 Routines 连起来看,这条路就更清楚了:你睡觉前设好任务,第二天早上回来直接看结果,开始变得越来越顺理成章。

说得直白一点,“AI 帮你值夜班”这件事,已经越来越不像一句玩笑话了。
API 多了一档,迁移也有新成本
对开发者来说,这次 API 侧也加了新东西。
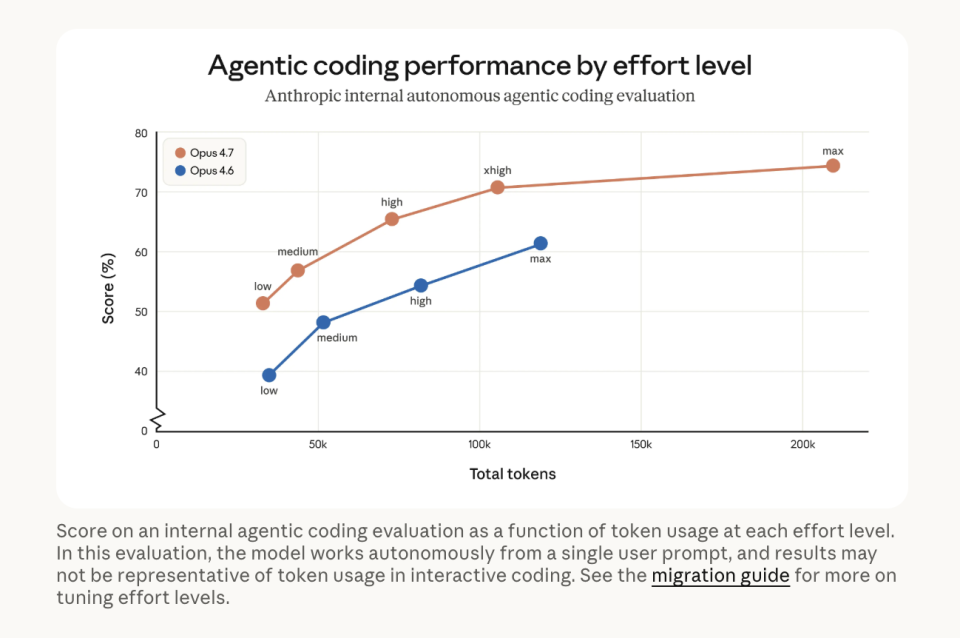
Anthropic 新增了 xhigh 推理等级,放在 high 和 max 之间。以前这两档之间跨度偏大,现在多了一个过渡层,调推理深度和响应速度时会更细一点。
另外,默认 effort 等级也从 high 提到了 xhigh。也就是说,很多情况下你什么都不用改,模型默认就会比以前更仔细。
还有一个 beta 功能叫 Task Budgets,让 Claude 在跑长任务时自己管理 token 消耗,知道哪些地方该多花力气,哪些地方可以省一点。还在测试阶段,但方向已经很明确,就是让长链路任务更像一套可控的生产流程。
迁移这边也不是完全没有代价。这次 tokenizer 更新后,相同输入内容对应的 token 数量,可能比以前多出 0% 到 35%。

好处是模型看到的信息更完整,输出更稳;代价是成本可能往上浮。如果你的工作流对 token 计费比较敏感,这一轮切换最好还是盯一下官方迁移指南。
真正更值得看的,不是某个参数,而是 Anthropic 这一串更新拼起来之后的方向
今天发的是一个能跑更长任务、会自己检查结果、视觉能力更强的新模型。
前两天上线的是 Routines,让 AI 可以开始按条件自己跑流程、自己盯任务。
再往前还有 1M context、子 Agent、/ultrareview,这些单看都像是一个个分散的小功能;但放在一起,它们指向的是同一件事:AI 需要人类频繁介入的地方,在一点一点变少。
你凌晨两点在睡觉,它在帮你审 PR;你周末在外面,它在帮你同步文档;你出门吃饭,它在帮你跑测试。
所以这次更新真正让人有压力的地方,不是“Opus 4.7 又强了一点”,而是 Anthropic 正在把模型能力、工具调用、代码审查、任务调度和成本控制,一块一块拼成一套更完整的行动系统。
留给人类的时间,到底是不是不多了,这件事可以继续争。但有一点已经很难否认:人盯流程、AI干执行的旧分工,正在被重新改写。
Claude Code 到底是什么?现在该怎么理解
如果现在还把 Claude Code 理解成“终端里一个能聊天的 Claude”,这个理解已经有点落后了。
更准确地说,它正在变成一个围绕任务执行展开的自主编程 Agent。它不只是补全代码、解释报错,还能读仓库、搜文件、改代码、执行命令、跑测试、做代码审查,并和 Routines、长上下文、子 Agent 这些能力连起来,承担更长链路的工作。
常见订阅里,Claude Pro 一般是 20 美元/月,Max 会更高;而 Opus 4.7 的 API 定价,这次仍然是每百万 token 输入 5 美元、输出 25 美元。
不过说实话,官方订阅对国内用户不太友好——需要海外信用卡,网络环境也得折腾。如果嫌麻烦想找个更省事的渠道,可以看看 Code80,真实订阅帐号转 API,换个 endpoint 就能直接用,体验跟官方一样。详情可以到官网了解:code.ai80.vip
常见问题
1. Claude Opus 4.7 这次最大的变化是什么?
不是单一 benchmark 提升,而是开始更系统地增强长任务执行能力:会自我验证、工具调用更稳、视觉能力更强,也更适合接更长链路的自主任务。
2. 自我验证为什么这么重要?
因为长任务最怕中间某一步悄悄跑偏,最后才发现结果不对。模型如果能先自己检查、自己修正,人就不用一直盯着每一环。
3. /ultrareview 更像什么?
更像 Claude Code 里的一轮深度代码审查命令。它不是简单扫一眼 diff,而是尽量把完整改动读一遍,把 reviewer 级别的问题找出来。
4. xhigh 推理等级有什么用?
它补上了 high 和 max 之间的空档,让开发者在响应速度、推理深度和成本之间做更细的平衡。
5. 这次更新对开发者最直接的影响是什么?
一方面是模型本身更适合长链路任务,另一方面是 Claude Code、Routines、长上下文这些能力正在开始连成一套完整工作流。开发者接下来要适应的,不只是“更强的模型”,而是“更能自己干活的 Agent”。
6. 国内开发者如果想更方便地使用 Claude 怎么办?
如果走官方路线,通常要处理支付、账号和网络环境这些现实问题。国内用户可以通过 Code80 更方便地使用。









评论前必须登录!
立即登录 注册