写在前面
这两个月,很多开发者都有同一种体感:Claude Code 不是不能用,而是“偶尔非常好,偶尔又像失忆”。
最让人焦虑的不是性能波动本身,而是你很难判断——到底是自己提示词写错了、项目太复杂了,还是工具链真的出了问题。
这次 Anthropic 直接发布复盘,把问题定位到 3 个具体变更:推理强度默认值、会话缓存清理逻辑、系统提示词长度限制。对于每天依赖 AI 编程的人来说,这份复盘的价值不只是“道歉”,而是把一件事讲清楚了:Agent 时代,稳定性本身就是核心能力。
不是“玄学降智”,而是三处工程改动叠加后的系统性波动
这波争议从 3 月开始发酵,社区里大量反馈集中在三个词:慢、忘、浅。
- 慢:响应时间拉长,复杂任务等待明显变久
- 忘:上下文像被反复清空,模型频繁重复或跑偏
- 浅:回答更短、更保守,复杂代码任务推理深度下降
Anthropic 给出的结论很关键:模型能力本身没有退化,Claude API 也未受影响;问题主要来自 Claude Code / Agent SDK 的运行框架变更,并且在不同流量切片上叠加后,形成了“广泛但不一致”的体验下降。
这其实比“模型参数变差”更值得重视,因为它说明 AI 编程工具的真实瓶颈,已经从“单次回答质量”转向“端到端系统协同质量”。
三个问题到底是什么:时间线、影响链路、修复动作
1)默认推理强度从 high 调到 medium,引发“更快但更笨”的感知
3 月 4 日,团队为了缓解高强度推理带来的超长延迟,把 Claude Code 默认推理强度从 high 调到了 medium。出发点是减少卡顿,但结果是复杂任务的智能表现被明显感知到下滑。
到 4 月 7 日,这个改动被撤回:默认回到更高智能路径,简单任务再按需降强度。只是这一轮改动已经影响到 Sonnet 4.6 和 Opus 4.6 的部分用户体验。
这件事的教训很直接:在编码场景里,“平均延迟”不是唯一优化目标。开发者通常更愿意多等几秒,换来一次能过的复杂改动,而不是更快地拿到一个需要返工的结果。
2)会话缓存清理 Bug:原本“一次性清理”,结果变成“每轮都清”
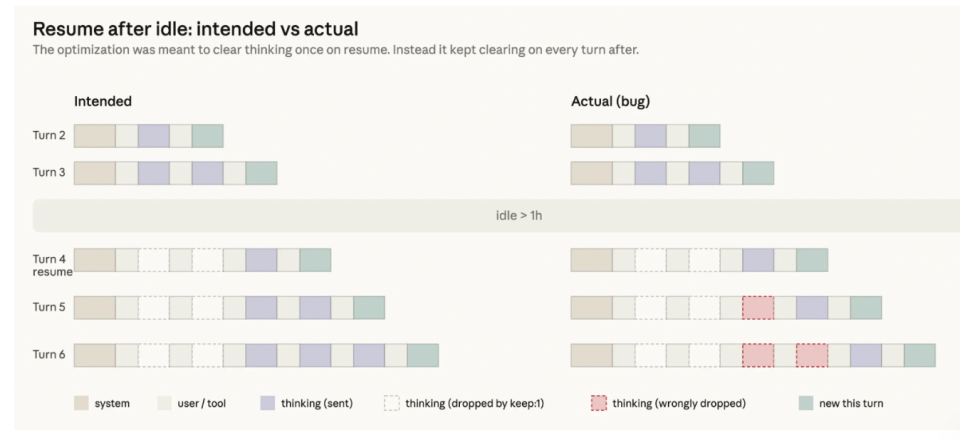
3 月 26 日上线的一项会话清理逻辑,本意是优化闲置会话恢复速度:超过一小时未使用的会话,在重新进入时清理旧思考内容。
问题出在执行条件:本该只触发一次的清理,因 Bug 在后续轮次持续触发。结果就是用户看到的“持续失忆、健忘、重复”——上下文刚建立又被冲掉。
该问题在 4 月 10 日修复,但期间同样波及 Sonnet 4.6 与 Opus 4.6。
对开发流程来说,这类问题杀伤力极大。因为 AI 编程最值钱的是“连续多步任务”——读代码、改代码、跑测试、再修复。只要上下文连续性不稳,整个链路就会退化成一次次从头开始。
3)系统提示词长度限制与其他改动叠加,压缩了复杂任务推理空间
4 月 16 日,系统提示词加入了更严格的长度限制:工具调用之间文本尽量不超过 25 词,最终回复尽量不超过 100 词。
这一条单独看像是“去冗长”的优化,但和其他提示词更新叠加后,副作用出现在代码任务上:模型在复杂问题里的解释、展开与中间思路被压缩,最终影响 coding 质量。
4 月 20 日,该变更被撤回;受影响范围提到 Sonnet 4.6、Opus 4.6 以及 Opus 4.7。
这一点对团队配置提示词也有现实意义:短不等于好。在复杂工程任务里,过度压缩输出往往会把“必要推理”一起砍掉。
这次复盘真正重要的地方:把 Agent 工程治理摆上台面
除了复盘问题本身,Anthropic 还给了后续改进方向,核心有三条:
- 提高内部员工使用“与外部一致版本”的比例,减少内外环境割裂
- 对系统提示词变更做更严格的消融评估与逐行影响测试
- 对可能影响智能水平的变更拉长观察期、细化灰度发布
另外,官方给出了补偿:截至 4 月 23 日,重置订阅用户使用限额。
对开发者而言,这轮事件至少确认了两件事:
- 你感知到的“降智”不一定是错觉,可能确实是系统层变更叠加
- 真正靠谱的 AI 编程平台,必须把“变更治理 + 观测 + 回滚”做成工程纪律
Claude Code 到底是什么?为什么大家会对它的稳定性这么敏感
Claude Code 不是传统意义上的代码补全插件,它更像一个能在真实项目里连续执行任务的自主 Agent:
- 读写项目文件,跨文件修改代码
- 执行终端命令,联动测试与构建流程
- 结合上下文进行重构、排错、迭代修复
- 在较长任务链路中保持目标一致性
也正因为它承担的是“多步任务执行”,一旦推理强度、缓存连续性或系统提示策略出现偏移,开发者的体感会非常明显。
订阅和计费上,官方主要是两条:一条是面向个人/团队的官方订阅方案,另一条是 Anthropic API 按调用量计费(实际价格以官方页面实时为准)。
不过说实话,官方订阅对国内用户不太友好——支付和网络环境都要额外折腾。如果你想省事一点,也可以看看 Code80,用真实订阅账号转 API,改 endpoint 就能直接接入现有工作流。详情见:code.ai80.vip
常见问题
Q1:这次“降智”是不是说明模型本身退化了?
A:目前披露信息指向运行框架与策略变更问题,不是模型参数能力整体退化;Claude API 也被明确说明未受同类影响。
Q2:为什么很多人会觉得它“时好时坏”?
A:因为多个改动发生在不同时间、不同流量切片,叠加后会形成不一致体验:有人主要感到慢,有人主要感到忘,有人主要感到浅。
Q3:对日常开发最实用的启发是什么?
A:复杂任务优先保证推理质量与上下文连续性,不要盲目追求“更短更快”;同时把关键链路(测试、回归、审查)放进可观测流程。
Q4:提示词是不是越短越好?
A:不是。复杂工程任务需要足够的思考空间,过度压缩往往会损伤任务完成质量。
Q5:国内开发者怎么更顺畅地用上 Claude Code?
A:如果不想处理复杂的支付与网络配置,国内用户可以通过 Code80 更方便接入。









评论前必须登录!
立即登录 注册