AI Agent 的竞争已经不只是“谁聊天更自然”。真正进入生产环境后,企业更关心的是:模型能不能连续调用工具、能不能修真实代码、能不能在复杂 UI 里完成任务、能不能从失败中恢复。
因此,评估 Agent 能力不能只看通用问答榜单,而要看一组更贴近真实工作的基准:SWE-bench、MCP Atlas、OSWorld、BFCL、Terminal-bench 等。它们分别对应代码工程、工具编排、桌面操控、函数调用和命令行执行能力。
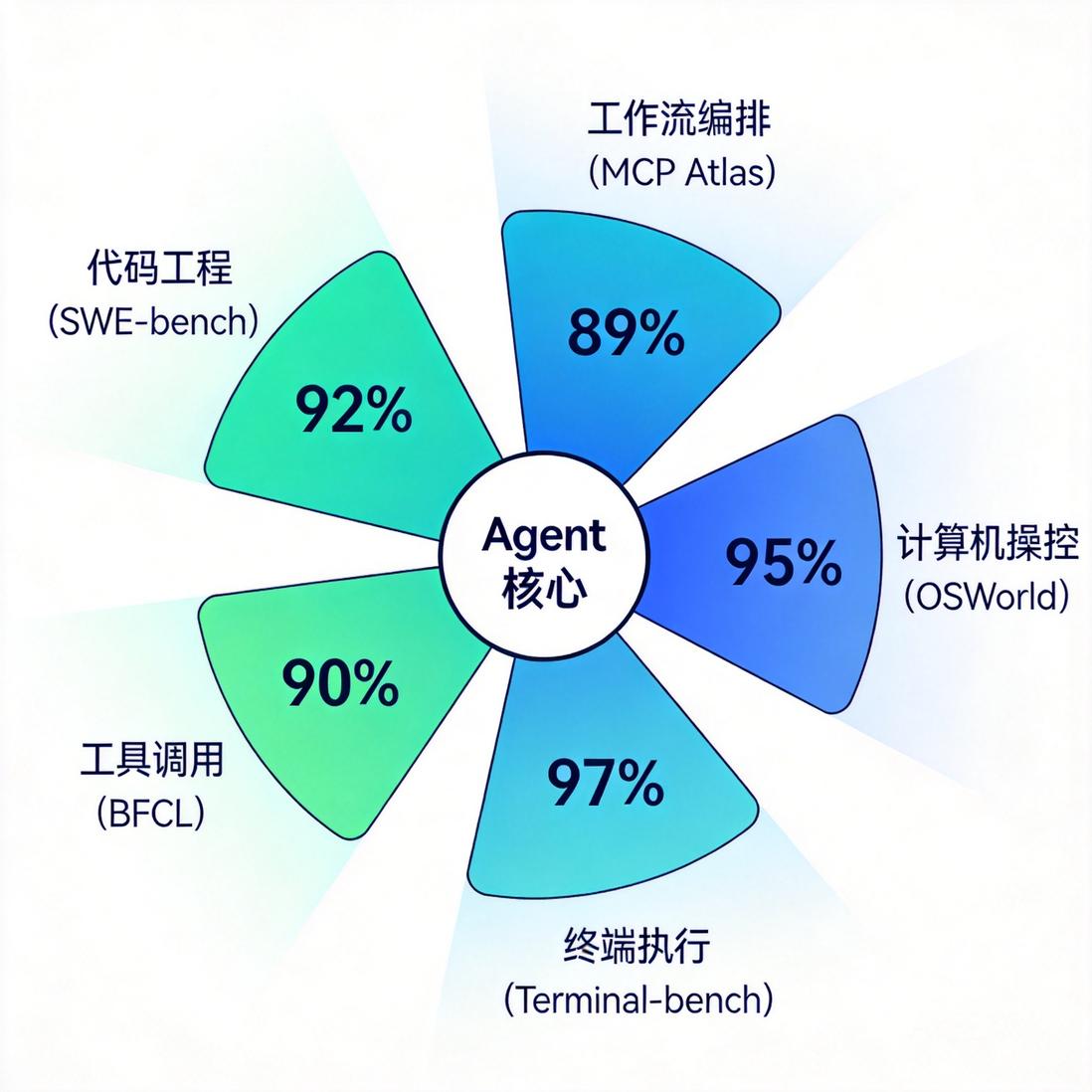
Agent 能力到底测什么
普通大模型评测通常关注知识问答、数学、推理、写作和代码片段生成。Agent 评测则更强调“完成任务”的全过程。
一个合格的 Agent 需要做到:
- 理解目标,而不是只回答问题;
- 拆解任务步骤;
- 调用工具、读写文件、执行命令;
- 根据错误信息调整策略;
- 在长任务中保持上下文一致;
- 最终给出可验证结果。
这也是为什么代码 Agent、浏览器 Agent、桌面 Agent、DevOps Agent 会使用不同基准。单一分数无法代表全部能力。
五类关键评测基准
| 维度 | 代表基准 | 主要考察 |
|---|---|---|
| 代码工程 | SWE-bench Verified / SWE-Bench Pro | 修复真实 GitHub Issue |
| 多步骤工作流 | MCP Atlas | 跨工具编排和长链路任务 |
| 计算机操控 | OSWorld | UI 理解、鼠标键盘操作 |
| 工具调用 | BFCL | 函数调用参数和结构化输出 |
| 命令行执行 | Terminal-bench | Shell 环境中的自主任务 |
选择模型前,先确定你的主战场在哪里。代码工程强,不代表桌面操控强;函数调用准,也不代表能稳定完成长链路自动化。
代码工程:Claude 仍是最值得关注的方向
SWE-bench Verified 要求模型在真实代码仓库里定位问题、修改代码并通过测试。它比“写一个函数”难得多,因为模型必须理解项目结构、依赖关系、测试失败原因和边界情况。
从公开报告看,Claude 4 系列在代码工程 Agent 方向仍然处于第一梯队。Sonnet 和 Opus 系列在复杂代码理解、长上下文阅读、补丁生成方面表现突出,适合:
- 修复真实项目 Bug;
- 给大型代码库补测试;
- 进行跨文件重构;
- 执行 Claude Code 类工作流;
- 处理长文档和长上下文工程任务。
但要注意,高分模式往往意味着更高推理成本。如果是高频低风险任务,未必需要每次都调用最强模型。
工作流和桌面操控:Gemini 的优势更明显
在多步骤工作流和计算机操控场景里,Gemini 系列的表现值得关注。MCP Atlas、OSWorld、Terminal-bench 这类基准更接近“让模型操作环境”的能力,而不是只让模型生成答案。
这类能力适合:
- 浏览器自动化;
- 跨应用数据搬运;
- 桌面任务执行;
- 工具链编排;
- 复杂命令行操作。
如果你的业务核心是“模型要能使用工具完成任务”,那么 Gemini 在部分工作流和 UI 操控场景里可能比纯代码基准更有参考价值。
GPT 和国产模型:更适合放进多模型路由
GPT-4o、o 系列模型以及国产模型如 Qwen、DeepSeek,在通用问答、代码生成、结构化输出和成本控制上都有各自优势。它们未必在每个 Agent 专项基准上都领先,但非常适合做多模型系统里的不同分工:
- 轻量问答与改写:使用低成本模型;
- 代码审查与复杂修复:切到 Claude 或更强推理模型;
- 工具调用和结构化输出:选择函数调用稳定的模型;
- 中文场景和成本敏感任务:评估 Qwen、DeepSeek 等国产模型;
- 多轮规划:用强模型做规划,低成本模型做执行和整理。
真正的生产系统很少只靠一个模型。更常见的架构是“任务分级 + 多模型路由 + 结果校验”。
按场景选模型,而不是按榜单选模型
| 使用场景 | 选型重点 |
|---|---|
| 代码工程自动化 | 优先看 SWE-bench、真实仓库修复效果 |
| 多步骤工具编排 | 优先看 MCP Atlas、函数调用稳定性 |
| 桌面/UI 自动化 | 优先看 OSWorld、Computer Use 能力 |
| DevOps 和命令行 | 优先看 Terminal-bench、错误恢复能力 |
| 成本敏感批处理 | 优先看单价、吞吐、失败重试成本 |
| 中文业务系统 | 加测中文指令、文档、专有词理解 |
三个选型原则很实用:
- 先用自己的真实任务做小样本测试;
- 把任务按难度分层,不要所有请求都打到最贵模型;
- 评估总成本时,把失败重试、人工复核和延迟都算进去。
构建 Agent 应用时,模型只是其中一层
生产级 Agent 通常不是“用户指令直接丢给模型”这么简单。更稳妥的架构应包含:
用户指令
→ 任务规划
→ 模型推理
→ 工具调用层
→ 执行结果解析
→ 错误恢复与重试
→ 校验与审计
→ 返回结果或进入下一步
其中工具定义质量非常关键。函数名、参数说明、返回格式、错误码都会影响模型调用准确率。很多 Agent 失败,不是模型完全不行,而是工具接口设计含糊、错误信息不可读、上下文管理混乱。
国内团队接入多模型时的工程取舍
如果团队要同时测试 Claude、Gemini、OpenAI 和国产模型,建议先做统一调用层,而不是在业务代码里分别适配每个供应商。统一入口的价值在于:
- 模型切换更快;
- 成本和用量更容易统计;
- 失败重试和降级策略可以集中实现;
- 评测脚本可以复用;
- 业务侧不必感知所有供应商差异。
在官方价格、API 兼容和国内访问之间做平衡时,可以把 Code80(https://code.ai80.vip)纳入评估,用于统一模型入口和多模型测试。重点仍然是看协议兼容、模型覆盖、价格透明度、日志策略和稳定性,而不是只看是否能快速调通。
FAQ
Q:SWE-bench 分数高,就一定适合所有 Agent 场景吗?
不一定。SWE-bench 主要反映代码工程能力,不能直接代表桌面操控、浏览器自动化或函数调用能力。
Q:高算力模式的分数能直接用于生产预估吗?
要谨慎。高算力模式通常通过多次采样和筛选提高成功率,成本和延迟也更高。生产环境需要按 ROI 判断是否值得。
Q:开源或国产模型能做 Agent 吗?
可以,但要结合具体任务测试。成本敏感、中文业务和私有化场景下,它们很有价值;复杂代码修复和长链路任务则需要更严格评估。
Q:企业应该多久重新评测一次模型?
建议按季度或重大模型更新后重测。Agent 能力迭代很快,半年之前的结论可能已经过时。
总结
2026 年的 Agent 选型已经进入“专项能力分化”阶段。Claude 更适合复杂代码工程和长上下文任务,Gemini 在多步骤工作流和计算机操控上值得关注,GPT 与国产模型则适合放入多模型路由,在成本、中文和通用能力之间做平衡。
最可靠的选型方式不是追单一榜单,而是拿自己的真实任务跑一组小型评测:成功率、成本、延迟、失败原因和人工复核成本一起看。只有这样,模型分数才会转化为业务可用性。








评论前必须登录!
立即登录 注册