> 面向想在国内项目中使用 Claude 的开发者和团队。本文从地区限制、账号风险、云厂商入口、兼容网关和自建代理四个角度,讲清楚各方案适用边界。
在国内调用 Claude API,真正的问题通常不是 SDK 怎么写,而是路径怎么选。Anthropic 官方服务在地区、账号、支付方式和网络访问上都有现实限制;即使代码层面只是一行 messages.create(),工程落地时也会遇到账号、网络、合规、计费和稳定性的组合问题。
所以在写代码前,先判断你要解决的是哪类问题:
- 只是个人试用
- 小流量项目验证
- 企业生产环境
- 已有海外云账号
- 需要在 Claude、GPT、Gemini、国产模型之间降级切换
不同目标,对应的路径完全不同。
为什么国内调用 Claude 会复杂
国内开发者常见阻碍有三类:
- 地区与注册限制:账号注册、手机号、支付方式可能需要海外条件。
- 网络连通性:国内服务器直连官方 API 可能超时、403 或不稳定。
- 风控风险:账号注册地、支付方式、出口 IP、调用流量异常都可能触发限制。
这意味着“能跑通 demo”和“能放进生产”是两回事。个人脚本可以接受偶发失败,生产系统则需要稳定性、账单、发票、权限和审计。
路径一:海外代理直连官方 API
基本思路
准备一个稳定海外出口,让国内客户端或服务器的请求通过代理访问官方 API。
常见方式包括:
- 本地代理
- 海外 VPS 代理
- 企业网络出口
- 固定 IP 网关
优点
- 接近官方原生体验
- SDK 和接口文档完全按官方来
- 不需要适配第三方协议转换
风险
- 代理 IP 质量决定稳定性
- 出口 IP 变化可能触发账号风控
- 海外账号和支付方式仍要解决
- 生产环境长期维护成本高
如果只是个人低频试用,这条路可以跑通;但如果是商业项目,把核心链路压在不稳定代理上,风险偏高。
路径二:通过云厂商模型服务
基本思路
Claude 模型可以通过部分海外云厂商模型平台调用,例如 AWS Bedrock、Google Vertex AI、Azure AI 等。企业如果本来就有海外云账号,可以把 Claude 放进已有云上架构中。
优点
- 企业级权限、账单、审计能力较完整
- 更适合生产环境
- 可和云厂商已有网络、日志、监控体系结合
成本与限制
- 通常需要海外云账号
- 可能需要海外支付与主体资质
- 国内云区域未必提供对应 Claude 模型
- API 形态与 Anthropic 官方 SDK 可能不完全一致
这条路适合已有海外业务、海外云资源和合规团队的公司。对于个人开发者或国内小团队,门槛通常偏高。
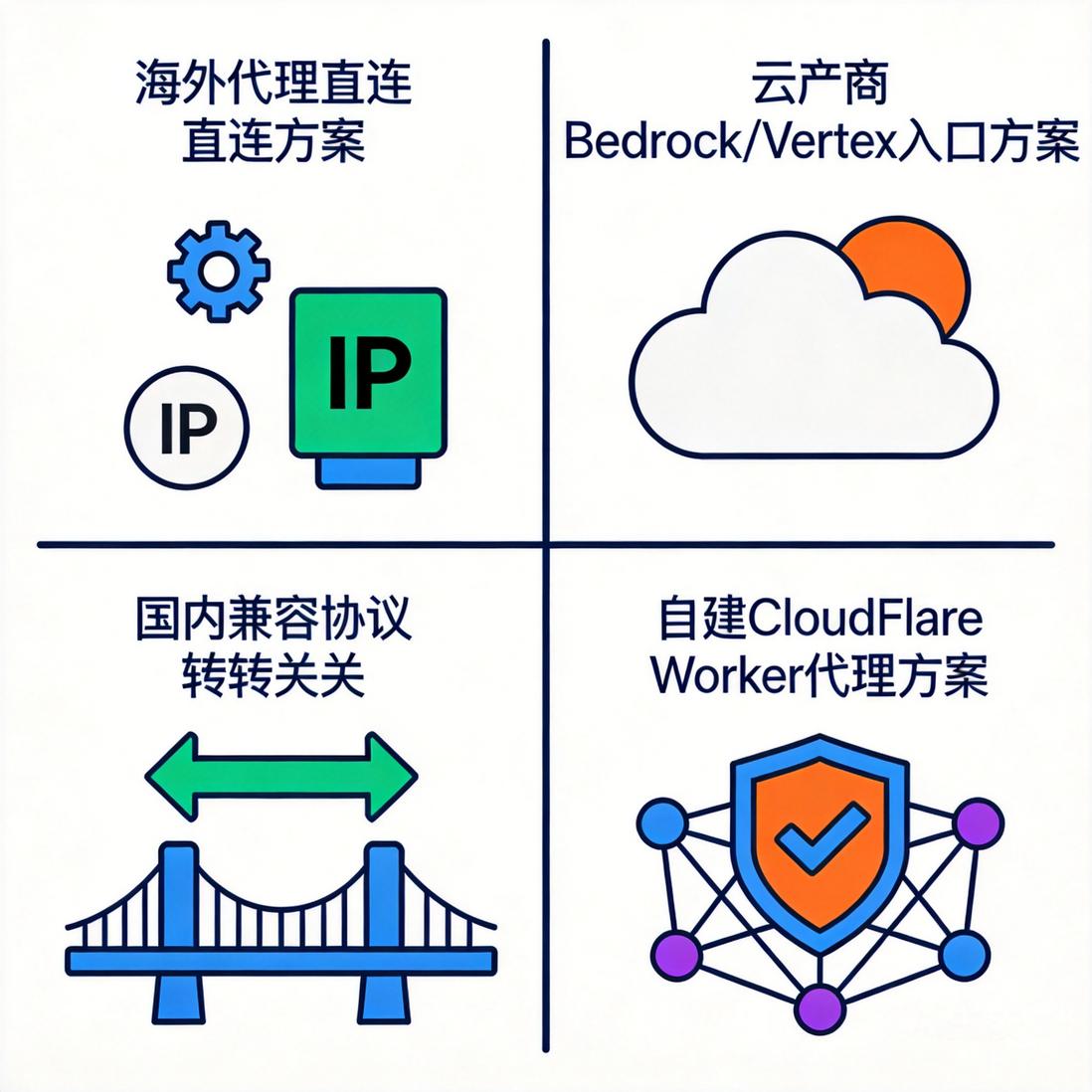
路径三:使用兼容协议的国内 API 网关
基本思路
由国内可访问的 API 网关提供 Claude、GPT、Gemini、DeepSeek、Kimi 等模型入口。开发者把 Base URL 和 API Key 换成网关提供的配置,业务代码尽量保持不变。
优点
- 国内网络访问更稳定
- 不需要管理海外账号和支付方式
- 可用人民币结算、开票、团队管理
- 多模型统一入口,便于做降级和 A/B 测试
- 适合 Cursor、Cline、Claude Code、Codex 等支持自定义端点的工具
需要重点验证
选择网关时不要只看“支持 Claude”四个字,还要验证:
| 维度 | 验证方式 |
|---|---|
| 协议兼容 | 是否支持 Anthropic Messages API,还是只支持 OpenAI Chat Completions |
| 模型真实性 | 输出风格、上下文能力、工具调用行为是否符合目标模型 |
| 稳定性 | 多轮调用、长上下文、并发请求是否稳定 |
| 计费透明 | token 统计、失败计费、倍率是否清晰 |
| 数据策略 | 是否保留请求、是否用于训练、是否支持企业隔离 |
如果你想在国内同时管理 Claude 和 OpenAI 兼容模型,可以考虑 Code80 这类统一入口;接入前建议先用小流量任务验证模型、延迟和计费明细。
路径四:自建反向代理
基本思路
如果你已经有合规的海外账号和服务器,可以用 Cloudflare Worker、Nginx、FastAPI 等方式自建一个轻量代理,把国内请求转发到官方 API。
伪流程如下:
国内客户端 → 自建代理域名 → 官方 Claude API
优点
- 控制权最高
- 可以统一日志、鉴权、限流
- 可根据业务做缓存、重试和降级
- 不依赖第三方中转平台
缺点
- 仍然依赖你的官方账号
- 出口 IP 和流量模式仍可能触发风控
- 需要自己维护安全、限流、密钥保护
- 不解决海外账号、支付和合规问题
这条路适合有工程能力、有海外资源、对数据路径要求更强的团队。不适合完全不想维护基础设施的个人用户。
四条路径怎么选
| 场景 | 更适合的路径 | 原因 |
|---|---|---|
| 个人低频试用 | 自建代理或海外代理 | 成本低,能快速验证 |
| 国内小项目验证 | 国内兼容网关 | 配置简单,访问稳定 |
| 企业生产、有海外云 | 云厂商入口 | 合规、审计、账单完善 |
| 数据路径要求高 | 自建代理 | 可控性强 |
| 多模型统一调度 | 国内兼容网关或内部网关 | 便于降级和模型切换 |
如果你只是想在 AI 编程工具中使用 Claude,优先检查工具支持哪种协议:
- Claude Code:需要 Anthropic API 兼容端点
- Cursor:可填 Anthropic Key,也可部分场景用自定义 OpenAI Base URL
- Cline / OpenClaw 等:通常支持多种 Provider
- Codex CLI:更偏 OpenAI 兼容协议,不等于直接支持 Anthropic Messages API
代码层面的抽象建议
无论选择哪条路径,都不要把 API 地址、模型名和 Key 写死在业务代码中。
推荐做法:
export LLM_BASE_URL="https://your-gateway.example.com"
export LLM_API_KEY="你的 API Key"
export LLM_MODEL="claude-sonnet-4-6"
业务代码只读取环境变量:
import os
base_url = os.environ["LLM_BASE_URL"]
api_key = os.environ["LLM_API_KEY"]
model = os.environ["LLM_MODEL"]
这样一旦某条路径不稳定,只需要替换配置,不必重写业务逻辑。
降级策略很重要
Claude 很强,但生产系统不能只有一个模型路径。建议至少准备:
- 主模型:Claude,用于复杂推理、代码分析、长文本处理
- 备用模型:GPT 或 Gemini,用于通用任务
- 本土模型:DeepSeek、Kimi、GLM 等,用于成本敏感或国内稳定性优先场景
- 规则降级:模型不可用时返回可解释错误,而不是无限重试
降级策略可以按任务类型拆分:
| 任务 | 主模型 | 备用模型 |
|---|---|---|
| 复杂代码审查 | Claude | GPT / DeepSeek R1 |
| 日常问答 | GPT / Claude | 国产通用模型 |
| 长文档总结 | Claude / Kimi | Gemini / 其他长上下文模型 |
| 低成本批处理 | 国产模型 | 小参数模型 |
安全与合规清单
接入前建议逐项确认:
- API Key 是否有最小权限控制
- 是否支持团队成员独立 Key
- 是否能查看用量和调用日志
- 是否有失败重试与限流策略
- 请求内容是否包含用户隐私或商业机密
- 是否需要数据脱敏
- 是否支持发票、合同、SLA
- 是否允许把数据传输到境外服务
个人项目可以轻量处理,企业项目必须把这些问题前置。
FAQ
国内调用 Claude 最省事的方式是什么
如果是小流量验证,使用兼容协议的国内 API 网关通常最省事;如果是企业生产,则要结合合规要求,在云厂商入口、内部网关和第三方服务之间评估。
自建代理是不是最安全
不一定。自建代理提升了路径可控性,但账号、出口 IP、密钥保护、日志脱敏、限流都要自己负责。没有安全工程能力时,自建也可能带来更大风险。
兼容网关会不会是假模型
有可能,所以要做验证。可以用长上下文、工具调用、模型特征问题、输出一致性和延迟表现综合判断,不要只看网页宣传。
Claude Code 能直接用 OpenAI 兼容接口吗
Claude Code 需要 Anthropic Messages API 兼容格式。只支持 OpenAI Chat Completions 的接口不能直接当作 Claude Code 后端,除非中间层做了协议转换。
总结
国内调用 Claude API 的关键是选路径,而不是只选 SDK。海外代理适合个人试用,云厂商入口适合已有海外云资源的企业,国内兼容网关适合快速验证和多模型统一管理,自建代理适合有海外账号与工程能力的团队。无论哪条路径,都应把 Base URL、Key、模型名配置化,并为关键业务准备降级模型,避免把系统稳定性绑定在单一账号或单一端点上。
评论前必须登录!
立即登录 注册