一期讲 Karpathy 式 LLM Wiki 的视频实操:三个文件夹、一个 Claude MD、按月 health check,让 AI 当知识库管理员,而不是继续让人自己维护插件栈。
本文整理自 Systems Made Better 这期视频。
它真正有价值的地方,不是再教你做一个更花哨的笔记系统,而是把知识库维护者从人换成了 LLM。三个文件夹、一个 Claude MD、定期 health check,本地 markdown 就能慢慢长成可复利的知识编译层。原视频:https://www.youtube.com/watch?v=ib74sLgjIBM
第一章:完整中文翻译
先说结论:这套方法的核心不是“知识都放哪”,而是“谁来负责整理和维护”。
多年来,我一直在用“第二大脑”。这可能是我见过最简单、但也最强的一套自学习个人知识库。它是用 Claude 搭出来的,我会直接把做法讲给你看。
2026 年刚开始时,AI 圈里一位很有分量的人,悄悄发了他自己怎么管理个人知识库。那其实就是一个第二大脑:你把信息放进去,让它们彼此建立连接,再反过来影响你的判断和行动。那个帖子被 10.5 万人收藏,但我猜真正动手搭的人几乎没有。问题就在这里。
这是我最近几个月看到最有用的一套 AI 工作流,而且已经可以直接落在 Claude 里。整个东西大概一个周末花 45 分钟就能搭出来。不需要 Obsidian,不需要向量数据库,不需要写代码,就是一个会不断自我完善的知识库。
这期视频我会讲三件事。第一,我会先用 60 秒把整体架构讲清楚。第二,我会现场把这个系统搭给你看。第三,我会展示一个 Claude skill,用来给这个知识库做审计、维护和持续改进。
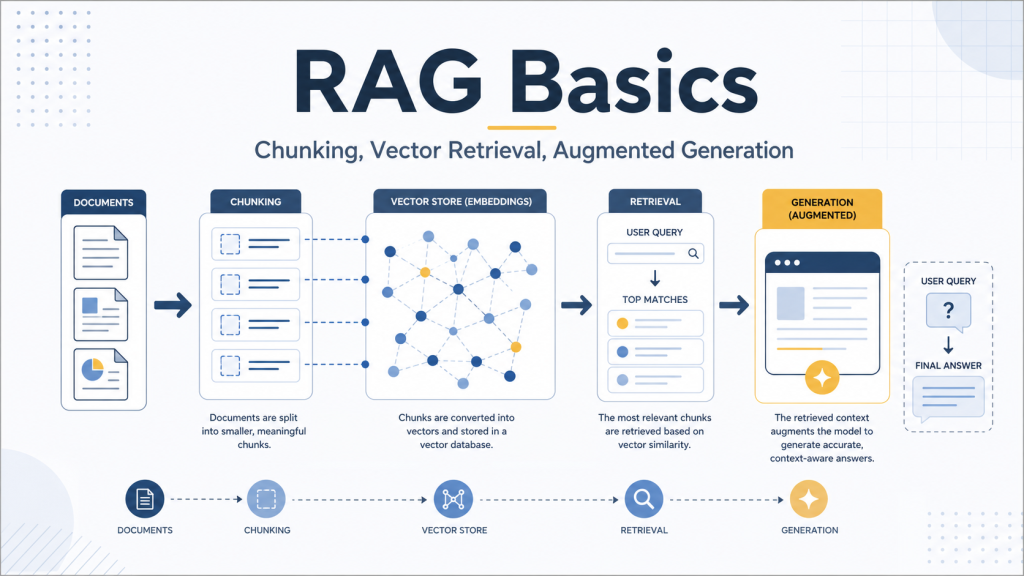
它的五步框架是这样的:先把结构搭好;再把你的资料一股脑倒进去;然后让 AI 把这些资料整理成 wiki;接着你开始提问,并把好的回答重新存回系统;最后配上健康检查,整个系统就会在这个循环里不断变好。
所以看完以后,你会知道这套系统到底是什么,为什么它在“简单”这件事上会胜过很多 Obsidian 插件流派,以及你怎么马上用 Claude 给自己搭一个。
我自己的感受是,第一天运行它时,这个知识库其实很普通;但到了第 100 天,它会变成一个别人复制不走的资产。你的视角、你的来源、你的判断,会被放在同一个地方。
先说最上层设计。整个系统其实就只有三个文件夹和一个文件,Claude 盯着这些东西工作。我把它放进自己的 Cowork OS 顶层目录里,以后也会把它做进模板里。
顶层有一个 Claude MD 文件,它相当于 schema,用来告诉 Claude 这个知识库应该怎么读、怎么用。
然后是三个文件夹。
第一个叫 raw。你可以把它理解成“杂物抽屉”。文章、笔记、截图、会议纪要,什么都往这里扔。你只负责保存,不负责整理。
第二个叫 wiki。AI 会把整理后的版本写在这里。这个目录原则上不应该由你手工编辑,主要交给 AI 去维护。
第三个叫 outputs。这里存的是 AI 生成的答案、briefing、报告。最好的一点在于,这些输出还可以继续喂回系统,用来修正和增强整个知识库。
就这么简单。没有数据库,没有 Obsidian vault 的复杂设置,只有你电脑上的文件夹和文本文件。
你可能会问:真的不需要 RAG、embedding 或向量存储吗?视频里的说法是,不需要。Karpathy 自己的知识库大约 100 篇文章、40 万词,LLM 处理起来没有问题:它会维护索引,按需读取相关内容。如果这套方式对一位顶级 AI 研究者都成立,对很多个人知识库和小团队场景,大概率也够用。
接下来是第一步:搭结构。
视频里是在 Claude 的 Cowork 环境里新建一个 knowledge 文件夹,再让 Claude 在里面创建 raw、wiki、outputs 三个子目录,并在根目录生成 Claude MD。作者还演示了一层更高的总目录,用来容纳多个不同主题的知识库,比如 productivity knowledge base。
然后他开始和 Claude 一起把规则写清楚:每个知识库怎么组织、什么时候 ingest、怎么做 monthly health check、要不要有一个 memory 文件记录最近一次处理时间,用来知道哪些 raw 文件是新来的、哪些已经处理过。
作者的结论是:这个 memory 文件值得加。它既是变更记录,也相当于系统自己的短期记忆。
第二步是 dump,也就是把资料倒进去。
这里有个很重要的观点:不要试图一开始就把知识库整理漂亮。你只需要把资料塞进 raw。文章、摘录、截图、会议内容、转写稿、PDF,都可以先进去。组织和归类,是 AI 的工作,不是你的工作。
作者现场演示了几种喂资料的方法。
一种是直接让 Claude 去读 Notion 数据库,通过 connector 找出 10 到 20 条高质量条目,写成 markdown 丢进 raw。
另一种是手工复制粘贴。比如看到一篇 Cal Newport 的 deep work 文章,直接把内容丢进去,让 Claude 另存成 markdown。
再一种是本地手工创建 md 文件。视频里甚至推荐了 Xcode:在 Mac 上新建一个 markdown file,命名后丢进文件夹就行。
如果你用 Obsidian,它的 web clipper 扩展也被点名表扬,因为它可以把网页一键转成干净的 markdown。
这个阶段还有一个细节:系统会维护一个 ingested registry,也就是记录哪些内容何时进入 raw。这样后面做增量处理时,会更稳。
第三步是 build the wiki。
作者给 Claude 的核心提示词大意是:读取 raw 里的全部内容,按照 Claude MD 里的规则,在 wiki 目录里编译出一个 wiki;先生成 index,再按主题生成独立页面,并把相关概念链接起来。
然后你就可以离开,让 AI 去干活。
它回来以后,给你的不再是原始资料堆,而是按主题整理好的页面、主题之间的连接关系、索引页,以及你原来并没有明确意识到的概念关联。
视频在这里给出的判断很明确:传统的 Notion 或 Obsidian,默认要求“你本人当图书管理员”。你要自己打标签、建目录、做双链、配插件,最后很多系统都死在维护成本上。Karpathy 那套方法的关键变化,是让 AI 变成图书管理员。你往里扔资料,Claude 负责整理、链接、摘要和索引,最后还帮助你把知识转成输出。
作者还补了一点经验:让 AI 写 wiki 时,最好先喂给它一套 anti-AI writing style 规则。否则 wiki 很容易写出那种模板腔、机械过渡很多、读起来不太像人写的内容。
第四步是开始提问,并把回答沉淀回系统。
作者拿一个 productivity knowledge base 做测试,问的是:我怎样才能在短时间内做成很多事,同时又兼顾精力、幸福感和健康?
Claude 的回答不是直接胡说,而是先读 index,再读相关 wiki 条目,再把不同作者和观点拼起来,最后给出一套有出处的答案。
但这一步暴露了一个设计问题:回答虽然不错,却没有自动进入 outputs。
于是作者马上修改了 Claude MD 的规则,要求以后凡是回答用户问题,都必须生成一份 report 存进 outputs,并且最好还能在对话里以可点击页面的方式展示出来。
然后他又继续追问:基于整个 wiki,这个知识库在“少做但做得更好”这个主题上,最大的三个理解缺口是什么?
系统给出的回答包括:
- 还缺“人通常是怎么从过载状态走出来”的材料
- 缺“怎么真正停下来”的机制
- 缺“在与他人协作时,如何维持这种生产力原则”的内容
也就是说,这个知识库不只是回答问题,它还会反过来暴露你目前知识结构的盲区。
第五步是 health check,也就是健康检查。
作者给出的理由很现实:AI 有时会写错一点东西,而你如果把这个错误保存回系统,后续回答就会悄悄建立在错误之上。所以知识库不能只 ingest、query,还得定期 audit。
他给出的手动 health check 提示词大意是:
- 审查整个 wiki
- 找出相互矛盾或数据不一致的条目
- 找出没有来源支撑的说法
- 检查 raw 里是否有还没被吸收的材料
- 建议还没建立的概念连接
- 提出几个值得新增的文章候选
更进一步,他还把这个检查做成了一个专门的 skill,并用 Claude 的 scheduled task 每月自动跑一次。
这个 health check skill 分成两个阶段。
第一阶段是 audit and file:读取 writing rules、change log、wiki、ingested 内容以及自上次检查以来生成的 outputs,然后跑一个七步审计:
- 矛盾检查
- 断链和孤立引用检查
- 来源溯源检查
- coverage 检查
- 过期内容检查
- 新条目建议
- 报告生成
第二阶段更适合交互场景:在给出报告后,再问你哪些发现要真正执行,哪些先保留。
视频里还展示了一次运行结果。系统指出:
- 某些主题存在 framing 上的冲突
- 有些说法引用不完整
- 有些 raw 文件还没被 ingest
- 还缺几个应当补建的主题页
作者的评价是:对于一个早期知识库来说,这种审计已经很值钱,因为它不是在帮你“多记一点东西”,而是在帮你维持知识结构的可信度。
他后来又演示了 scheduled task 版本,跑一次大约 12 分钟,在他的 5x Max 计划里大概吃掉了当前 session 45% 的额度。所以视频没有把它说成“零成本”,而是明确提醒:这类 health check 很耗额度,更适合按月跑,不适合天天跑。
最后作者给出的结论是:第一天运行这套系统时,它并不会神奇到让你立刻起飞;你只是把一个周末塞进去的材料整理得更像样而已。但到第 100 天,它会变成一个真正有复利的资产。每一次会议记录、每一次好回答、每一次回写,都会让这个知识库更像你自己的长期判断系统。
如果只记一句话,那就是:你不需要再亲自当那个最勤劳的整理员。你要做的,是把资料放进去、提问题、做审计,然后让 AI 帮你把知识编译成一个可累积、可查询、可持续改进的系统。
第二章:分析
这期视频能打动人,不是因为它发明了什么全新技术,而是因为它把一个经常被做复杂的事情,硬生生压回了文件系统这个最朴素的层面。
它真正讲清楚的,不是“第二大脑”,而是“谁来维护第二大脑”
传统笔记工具的问题,往往不在收集,而在维护。你当然可以在 Obsidian 里做双链、标签、索引、模板、Dataview、插件流水线,但维护者一直是你自己。视频里最有价值的一刀,是把这个角色从“人”切换成了“AI”。
这跟你知识库里对 Karpathy LLM Wiki 的总结是对齐的:关键不在于每次 query 时临时检索,而在于有没有一个持续维护的知识编译层。你自己仓库里的判断也很接近——RAG 记住的是数据,Wiki 记住的是已经被整理过的理解。
它的优点非常现实
第一,门槛低。
视频反复强调三件事:三个文件夹、一个 Claude MD、没有向量库。这种设计对大多数人友好,因为它不要求你先搭一套检索基础设施,也不要求你先学一堆数据库和 embedding 术语。
第二,可见性强。
raw、wiki、outputs 全都落在本地文件里。你能看到系统到底吸收了什么、改写了什么、输出了什么。这比很多“聊天即系统”的黑盒产品强,因为问题一出来,你至少知道该去哪一层排查。
第三,复利逻辑清楚。
这套方法最有意思的地方,不是单次回答更聪明,而是回答可以回写,health check 还能继续纠偏。这样知识库不会只是静态仓库,而会慢慢长成一个有反馈回路的系统。
但这视频也有明显的乐观偏置
1. 它把“不要 Obsidian”说得太轻了,实际上只是把 Obsidian 降成了查看器
视频口头上说“不需要 Obsidian”,但它自己又推荐 Obsidian web clipper,还大量依赖 markdown 文件这种 Obsidian 极度友好的载体。严格说,这不是抛弃 Obsidian,而是把 Obsidian 从“核心系统”降级成“一个不错的壳”。
这其实和你现在的做法更接近:Obsidian 最有价值的未必是它的插件生态,而是它作为本地 markdown 知识界面的稳定性。
2. 它低估了规模问题
视频引用了一个很诱人的数字:Karpathy 的知识库大约 100 篇文章、40 万词,LLM 也能 handle。但这个量级并不自动等于“谁都能这么干”。
你知识库里的实证审计已经把这个问题讲得很清楚:公开讨论里几乎没有真正严格的 head-to-head benchmark,很多“比 RAG 好多少”的数字都很可疑。更现实的判断是:在小到中等规模、主题边界明确时,Wiki 模式非常顺;但一旦进入高频更新、多用户、大体量、跨格式异构语料,RAG 或 Hybrid 迟早要回来。
换句话说,这视频适合拿来指导“个人知识库”或“小团队专题知识库”,不太适合直接外推到企业级通用知识系统。
3. 它讲了 health check,但还没真正解决幻觉累积的根问题
视频已经意识到错误会被写回系统,所以才加了 health check。这是优点。但它的审计逻辑本质上还是让 LLM 去检查 LLM 写出来的东西。这样做当然比不检查强,但并不等于问题被彻底解决。
你库里的那篇《AK LLM Wiki 实证审计》其实已经指出了这一点:公开案例里,真正缺的不是“会不会写 wiki”,而是“有没有同语料、同问题、同评测口径下的基线对比”。没有这个,很多“看起来更聪明”的感觉,最后还是停留在主观体验。
这期视频最适合谁看
适合的人
- 已经被 Obsidian / Notion 组织成本折磨过的人
- 有一批固定主题资料,想做专题知识库的人
- 想把 Claude 从“聊天机器人”升级成“本地知识代理”的人
- 接受 markdown / 文件系统工作流的人
不太适合的人
- 想一步到位做超大规模企业知识检索的人
- 需要多人强协作、权限控制、实时同步的人
- 对回答可验证性要求极高,但又不愿意做额外审计的人
- 不愿意维护规则文件、change log、health check 的人
如果把这期视频压成一句话
它真正提供的,不是一套完美知识管理方案,而是一种更务实的工程立场:先别急着做“更聪明的检索系统”,先试着做一个“能持续整理、持续回写、持续审计”的本地知识编译层。
这也是为什么它和你现在的 wiki 体系会天然相容。你已经不缺“记东西”的地方了,真正稀缺的是一套能把 raw、wiki、analysis、query 串成闭环的机制。视频最有价值的,不是让人重新迷上第二大脑,而是提醒人:维护知识库这件事,本来就应该尽量从人手里拿走。
我的判断
如果只是个人研究、专题学习、写作素材沉淀,这套方法值得上手,而且比多数“插件越装越多”的笔记流派更接近长期可维护。
但如果有人把它讲成“RAG 已死”或者“通用知识库未来只有 Wiki”,那就过头了。更准确的说法应该是:Wiki 适合把高价值、可沉淀、可复用的核心知识先编译出来;RAG 适合承接大规模、长尾、动态和异构的部分。真正成熟的系统,大概率还是混合形态。






评论前必须登录!
立即登录 注册