
写在前面
如果你最近还把 AI 编程理解成“补全几行代码”,那 2026 年 2 月 5 日这一天,可能就是一个分水岭。
同一天里,OpenAI 放出了 GPT-5.3 Codex,Anthropic 推出了 Claude Opus 4.6。重点不只是两个新模型一起发布,而是它们都在把“AI 写代码”往更激进的方向推:不再满足于帮你补全,而是开始接手调试、执行命令、跨文件协作,甚至像一支小团队那样分工干活。
问题也随之变了。现在真正该问的,已经不是“哪个模型更聪明”,而是:你需要的是一个擅长落地工程任务的执行型 Agent,还是一个更适合长上下文推理和多 Agent 协作的战略型 Agent?
逐行手写代码的时代,正在被重新定义
这波更新最值得警惕的一点,是两家公司都在公开把 AI 从“助手”往“协作者”甚至“独立工作者”推进。
OpenAI 对 GPT-5.3 Codex 的定位,不再是传统 IDE 里的补全模型,而是可以操作电脑、调试代码、部署应用、写产品文档的专业 Agent。Anthropic 那边也一样,Claude Opus 4.6 不只是继续堆模型能力,而是把 100 万 token 上下文和 Agent Teams 一起端出来,明显是在押注更复杂、更长期的软件协作流程。
这意味着什么?很简单:以后拉开差距的,不只是“谁会不会写 prompt”,而是谁先把 AI 接进真实工作流。
以前很多工程任务卡在人要自己来回切上下文:读代码、看报错、查文档、改文件、跑命令、再回头修。现在新一代编程 Agent 的目标,是把这些动作串起来,尽量让 AI 自己跑完整条链路。你还在把 AI 当搜索框,别人已经把它当半个工程同事了。
GPT-5.3 Codex 在做什么:从“会写代码”升级成“会在电脑上干活”
它的核心定位,不是补全器,而是软件工程 Agent
先看 OpenAI 这边。GPT-5.3 Codex 的野心很明确:它不想只待在 IDE 里当一个给建议的工具,而是想接手你在电脑上的整段专业工作流。
按照发布信息,GPT-5.3 Codex 被描述为一个能覆盖完整工作生命周期的 specialist agent。说白了,它想做的不是“帮你写一段函数”,而是更像一个能独立推进任务的软件开发者:调试、部署、文档整理,这些都在它的目标范围里。
其中一个很有冲击力的细节是,OpenAI 提到 Codex 是“第一个在创造自己这件事上发挥关键作用的模型”。他们已经拿它去调试自己的训练流程、协助管理部署。这件事的象征意义比参数表更大——AI 不只是写业务代码,已经开始参与 AI 系统本身的工程闭环了。
它的强项很集中:软件工程和命令行执行
从公开数据看,Codex 的优势非常偏工程执行面。
- SWE-Bench Pro:56.8%
- Terminal-Bench 2.0:77.3%
这两项指标都不是那种“看着热闹、离工作很远”的 benchmark。SWE-Bench 系列更接近真实软件工程问题,Terminal-Bench 则直接考命令行环境下的执行能力。尤其是 77.3% 的 Terminal-Bench 2.0 分数,说明它在 shell、命令流、工程操作这类事情上,已经不是“能试试”,而是有明确竞争力。
新的 Codex macOS App,暴露了 OpenAI 的真正路线
OpenAI 同时还发了 Codex 的 macOS 应用,这个动作其实很关键。
它不是简单换个客户端,而是把 Codex 包装成一个“多 Agent 调度中心”:你可以在桌面上同时管理多个 Agent,让它们并行处理不同任务。这个方向很像把个人开发者升级成一个小型调度者——你发号施令,多个 AI 去各自干活。
所以如果你本来就偏工程落地,想把明确任务批量交出去,Codex 的方向会很有吸引力。它像一个执行力特别强的操作型 Agent。
Claude Opus 4.6 在做什么:把长上下文推理和多 Agent 协作往前推了一大截
Anthropic 这次不是只在提性能,而是在提“协作密度”
再看 Claude Opus 4.6,它延续的还是 Anthropic 一贯的路线:可靠、可控、适合复杂知识工作,但这次把尺度拉得更大了。
Claude Opus 4.6 被定位成 Anthropic 目前最强的顶级模型,重点服务复杂知识工作、大规模信息推理,以及企业里的协作式 Agent 工作流。和 Codex 那种“我来把工程动作做完”的味道不太一样,Opus 4.6 更像一个能在大范围上下文里持续思考、持续统筹的模型。
100 万 token 上下文,不只是数字更大
它最显眼的更新,是 100 万 token 上下文窗口,目前还是 beta。
这个能力解决的是很多开发者都遇到过的“上下文腐烂”问题:对话拉长之后,模型开始忘前面说过什么;仓库一大,前后信息关联就开始断裂。100 万 token 的意义,不是让你炫耀“我能塞进去一本书”,而是让模型在超长材料里还能保持思路不断线。
你可以把整套代码库、大量文档、长规格说明、历史讨论一起喂进去,让它基于全局信息推理,而不是在局部片段里瞎猜。对大型代码库、复杂产品需求、长文档协同,这个提升非常实际。
Agent Teams 才是这次最像“下一代工作方式”的东西
Claude Opus 4.6 另一个很重要的能力,是 Claude Code 里的 Agent Teams。
这个功能的意思不是“开几个窗口同时聊天”,而是让多个 AI Agent 在同一个项目里协同工作。比如一个管前端、一个管 API、一个管数据库迁移,它们像人类软件团队一样拆任务、协作推进。
这一点和 Codex 的多 Agent 管理虽然都在讲 Agent,但哲学不太一样:
- Codex 更像你亲自调度一群执行者;
- Opus 4.6 更像你给定目标后,让一支 AI 小队自己分工协作。
如果说 Codex 偏“操作系统级工程代理”,那 Opus 4.6 更像“项目级协作代理”。
它的 benchmark 也说明了方向不同
Opus 4.6 在复杂推理和知识工作类 benchmark 上表现更强,比如 GDPval-AA 和 BrowseComp 都是行业领先。文章还提到,通过特定 prompting 的改造方式,它在 SWE-Bench Verified 上拿到了 81.42%。
这很说明问题:Opus 4.6 不是那种“默认就把所有工程 benchmark 全部碾压”的路线,而是当任务需要长链路推理、全局理解、复杂引导时,它会显出更细腻的能力。
另外,它还在往办公生产力工具里延伸,比如 PowerPoint 研究预览、对 Excel 类工具更强的配合能力。这意味着 Anthropic 想做的,不只是开发者模型,而是更全面的知识工作底座。
把数据摆在一起看:谁更适合干什么,其实已经很清楚了
原文里给了一组对照表,放在一起看会很直观:
| Benchmark | GPT-5.3 Codex | Claude Opus 4.6 | 更强一方 |
|---|---|---|---|
| Terminal-Bench 2.0 | 77.3% | 65.4% | GPT-5.3 Codex |
| SWE-Bench Pro | 56.8% | 未公布 | GPT-5.3 Codex |
| SWE-Bench Verified | 80.0% | 81.42%(特定改造) | Claude Opus 4.6 |
| OSWorld-Verified | 64.7% | 72.7% | Claude Opus 4.6 |
| GDPval-AA | 低于 Opus | 行业领先 | Claude Opus 4.6 |
| BrowseComp | 未公布 | 行业领先 | Claude Opus 4.6 |
看到这里,其实不太需要再争“谁绝对更强”。更靠谱的结论是:
- Codex 更像工程执行特化型选手,在命令行、软件工程、确定性任务落地上更猛。
- Opus 4.6 更像长上下文推理和复杂协作型选手,在全局理解、复杂知识工作、Agent 团队协同上更强。
如果你的任务是“这件事怎么都已经定义清楚了,你去把它做完”,Codex 的风格通常更对路。
如果你的任务是“这件事涉及很多历史背景、很多文档、很多模块,还得边想边拆边协作”,那 Opus 4.6 的优势就更容易显出来。
真正拉开差距的,不只是 benchmark,而是 Agent 哲学
数字归数字,这两家最值得关注的,其实是它们对“AI Agent 应该怎么工作”的理解不同。
Codex:从代码生成器走向“电脑操作员”
Codex 的路线图很明确:让一个用户像指挥中控台一样,管理一群强执行力 Agent。你是总控,Agent 是执行层。它强调的是可操作性、可调度性、工程动作的一致性。
这种模式适合什么场景?特别适合软件开发里那些任务清晰、动作链条长、但不一定需要反复战略讨论的工作。比如修 bug、跑部署、批量改代码、处理命令行流程,这些都很贴它的定位。
Opus 4.6:从强模型走向“AI 团队”
Opus 4.6 则更强调 Agent 之间的协作分工。它不是让你时时刻刻盯着每个 Agent 怎么执行,而是希望你更像项目负责人:给目标、给边界,再让一支 AI 团队自己规划怎么完成。
这种模式特别适合复杂项目。因为真正难的往往不是“把一件事做掉”,而是“把多个模块、多个角色、多个约束统一起来”。Agent Teams 想解决的就是这个层面的问题。
所以如果你非要一句话总结二者差异,可以这么理解:
- Codex 更像执行层超级个体
- Opus 4.6 更像协作层智能团队
安全和企业可用性,为什么这次也必须一起看
模型越像“能自己干活的同事”,企业越不可能只盯着效果看,还得盯着安全和合规。
OpenAI 在 GPT-5.3 Codex 上给出的信息是,它在网络安全任务上被归类为“High capability”,既覆盖防御也覆盖进攻类能力。为此,OpenAI 推出了 Trusted Access for Cyber 框架,并用 1000 万美元基金推动 AI 驱动的网络安全防御。
Anthropic 这边的叙事更延续自己一贯的风格:Claude 的安全设计建立在 Claude Constitution 这套原则之上,同时企业侧提供 SOC 2、ISO 27001、HIPAA readiness 等合规能力,并通过 Trust Center 对外说明。
这部分看起来不像“模型能力对比”里最热闹的点,但对企业来说反而很关键。因为把 Agent 接进工作流,问的从来不只是“它能不能做”,还包括“它出了问题能不能控”“能不能过合规”“能不能放心进核心流程”。
价格和可用性:两边都不便宜,而且使用方式完全不同
GPT-5.3 Codex 怎么用
根据原文,GPT-5.3 Codex 已经面向付费 ChatGPT 用户开放,可以通过 Codex app、CLI 工具和 IDE 扩展使用。
不过它的 API 还在逐步开放阶段,API 定价暂时没有正式公布。这意味着如果你更偏个人开发体验,Codex 已经能上手;但如果你是团队,准备基于 API 做更深集成,那还得等更完整的开放节奏。
Claude Opus 4.6 怎么用
Claude Opus 4.6 则已经能通过 Claude API 直接使用,而且价格沿用了前代:
- 输入:5 美元 / 百万 token
- 输出:25 美元 / 百万 token
- 当 prompt 超过 20 万 token 时,提升到 10 / 37.5 美元
这套定价的麻烦在于,长上下文和深度推理很强,但账单也更容易失控。尤其是你真的开始把大仓库、大文档、大任务往里塞之后,成本会比表面数字更有体感。
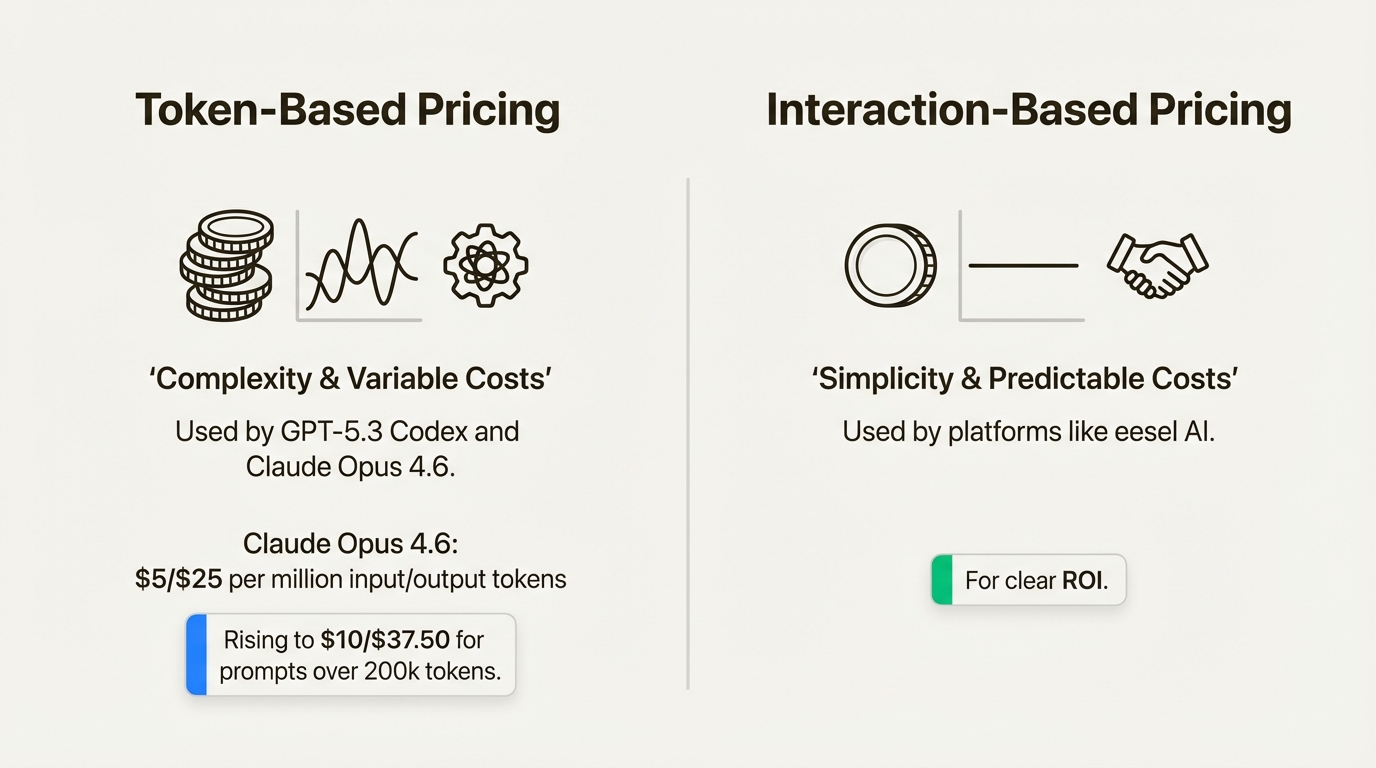
所以价格层面也能看出两边差异:Codex 目前更像产品化入口先行,Claude Opus 4.6 则是 API 侧路径更清晰,但成本模型更需要精打细算。
到底该选谁?别再问“最强”,先问你的任务长什么样

如果你的核心目标是:
- 自动化很具体的软件工程任务
- 更强的命令行执行能力
- 让 Agent 真正在电脑上操作和交付
- 把明确需求快速做完
那 GPT-5.3 Codex 会更像你要的工具。
如果你的核心目标是:
- 在超长上下文里做复杂推理
- 跨大代码库、大文档、大量历史信息持续工作
- 需要多个 Agent 分工合作
- 更看重全局理解和复杂项目协调
那 Claude Opus 4.6 更值得重点看。
换句话说,Codex 更适合“高确定性执行”,Opus 4.6 更适合“高复杂度协作”。
Claude Opus 4.6 到底是什么?普通开发者能拿它做什么?
如果你之前只把 Claude 理解成一个聊天模型,那这次升级里最该重新认识的,其实是它在工程工作流里的位置。
Claude Opus 4.6 不是传统意义上的代码补全工具。它更像一个能承担复杂任务的自主 Agent:能处理超长上下文,能读懂大规模信息,能在 Claude Code 里配合多 Agent 协作,还能在复杂知识工作和工程任务里保持比较稳定的推理质量。
落到实际使用场景里,它比较适合这些事:
- 读大型代码库并做跨模块分析
- 带着大量设计文档、需求背景一起规划改造方案
- 多文件重构、复杂调试、长期任务拆分
- 让多个 Agent 角色并行推进同一个项目
官方使用路径也比较清晰:你可以通过 Claude API 直接接入;如果是订阅制用户,通常会接触到 Claude Pro、Claude Max 这类套餐,不同档位对应可用模型和使用额度不同。API 公开价格如上,Opus 4.6 维持前代定价,但长 prompt 会进入更高阶梯。
不过说实话,官方订阅对国内用户不太友好——需要海外信用卡,网络环境也得折腾。如果嫌麻烦想找个更省事的渠道,可以看看 Code80,真实订阅帐号转 API,换个 endpoint 就能直接用,体验跟官方一样。详情可以到官网了解:code.ai80.vip
常见问题
Q1:GPT-5.3 Codex 和 Claude Opus 4.6 的最大区别是什么?
A:核心区别在定位。GPT-5.3 Codex 更偏软件工程执行和命令行操作,Claude Opus 4.6 更偏长上下文推理、复杂知识工作和多 Agent 协作。
Q2:单看 benchmark,谁赢了?
A:没有绝对赢家。Codex 在 Terminal-Bench 2.0 和 SWE-Bench Pro 这类工程执行指标上更强,Opus 4.6 在 GDPval-AA、BrowseComp、OSWorld-Verified 以及特定条件下的 SWE-Bench Verified 上更亮眼。
Q3:如果我是开发者,应该优先关注哪个能力?
A:看你的任务形态。明确需求、强调执行效率,就优先看 Codex;任务复杂、上下文巨大、需要协作拆分,就优先看 Opus 4.6。
Q4:Claude Opus 4.6 的 100 万 token 真有用吗?
A:对小任务未必,但对大仓库分析、长文档理解、跨多模块推理非常有用。它解决的不是“能不能塞更多文本”,而是“模型在超长上下文里还能不能持续保持理解”。
Q5:为什么很多人开始把 AI 编程工具理解成 Agent,而不是聊天机器人?
A:因为这一代工具已经不只回答问题了,而是在读文件、跑命令、调试、协作、拆任务,正在向真实工作流的执行者演进。
Q6:国内用户如果想更省事地用上 Claude 能力,有什么办法?
A:如果你不想折腾支付和网络,国内用户可以通过 Code80 更方便地使用。








评论前必须登录!
立即登录 注册