写在前面
很多人第一次用 Claude Code,会有一种“很强,但有点难驾驭”的感觉。
问题通常不在模型本身,而在使用方式:需求说得太空、任务一股脑丢进去、会话越聊越长不收敛、成本和上下文也不管,最后就会觉得“AI 也不过如此”。
这篇我把原文的 16 个技巧重新按真实开发流程整理了一遍。你可以直接对照自己的日常习惯:哪些动作在拉低效率,哪些动作能让 Claude Code 真正进入“干活状态”。
为什么同样是 Claude Code,有人提效 3 倍,有人越用越累?
核心差距其实就三件事:
- 会不会把问题定义清楚(而不是只会说“帮我修一下”);
- 会不会管理上下文和成本(而不是聊到爆再抱怨慢和贵);
- 会不会把高频动作做成工作流(而不是每次从头打字)。
换句话说,Claude Code 不是“你说一句、它补一段”的传统补全工具,它更像一个终端里的执行型 Agent。你给它的上下文越结构化,它的产出就越像资深工程师,而不是随机代码生成器。
16 个技巧,按实战工作流重排
一、先把任务喂对:提示词与拆解方式(技巧 1-3)
1)把需求说具体,不要让模型猜
“修复这个漏洞”这种话,Claude Code 只能靠猜。
更好的说法是:
> 修复用户登录时,不输入密码导致的空指针错误。
这样它会立刻定位到:入口、异常路径、预期行为,而不是先花很多轮追问你到底想改什么。
2)复杂任务分步,小任务可一口气做完
如果是小模块,直接一次性描述完整目标,通常更快。
如果是大需求,建议拆成步骤:
- 给用户 API 新增一个接口;
- 为请求字段加校验;
- 补测试用例;
- 最后再统一回归。
这样每步都能 review 和回归,避免上下文过长导致输出截断或风格漂移。
3)动手前先让它“读懂项目”
在改代码前,先让 Claude Code 回答你的“理解型问题”,比如:
- 当前项目数据库表结构是怎样关联的?
- 现有错误处理链路是怎样的?
这个动作会显著减少它后续写错风格、写偏架构的概率。
二、把交互效率拉满:快捷操作与会话控制(技巧 4-9)
4)快捷键和斜杠命令,别硬打字
高频操作建议直接肌肉记忆:
/:查看所有斜杠命令;- 上下方向键:翻历史命令;
Tab:补全命令;Option + Enter:换行;Ctrl + C:退出。
5)免授权模式可以提速,但要分场景用
命令:
claude --dangerously-skip-permissions
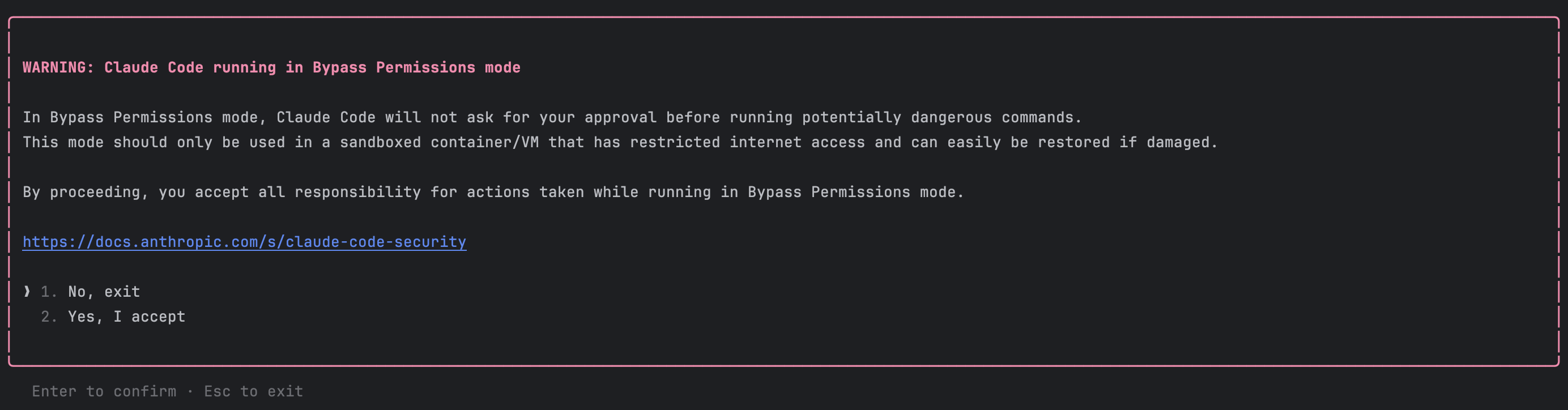
确认后会进入 Bypassing Permissions 模式:
你也可以做 alias:
alias claude='claude --dangerously-skip-permissions'
这个模式适合你完全信任的本地仓库;对陌生代码库、生产相关目录,建议保持授权确认,安全第一。
6)“think”有等级,别默认开最大火力
思考强度是分级的:
> think < think hard < think harder < ultrathink
强度越高,推理预算越大,成本也越高。原文示例里一个简单问题就耗费了约 0.06 美元:
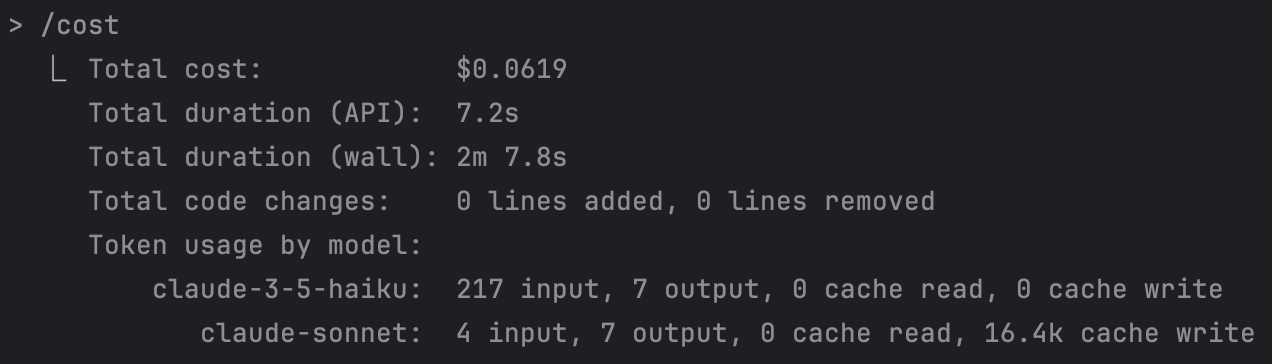
建议:默认中等强度,遇到复杂架构决策再拉高。
7)指令下错了,立刻 ESC 打断
AI 执行方向跑偏时,不要等它做完,直接 ESC:

8)多模态输入:截图 + 指令,定位问题更快
你可以直接贴图让 Claude Code 分析报错、UI、流程图:
常用提示词:
- 这个截图显示了什么问题?
- 这个错误大概率由什么引起?
- 按这张设计图生成前端页面。
9)会话恢复:continue / resume 都要会
非交互模式:
claude --continue/claude -c:直接续最近会话;claude --resume/claude -r:先选会话再恢复。
交互模式下可以用 /resume:

三、长期可用的关键:记忆、Git/Linux、模型和成本(技巧 10-15)
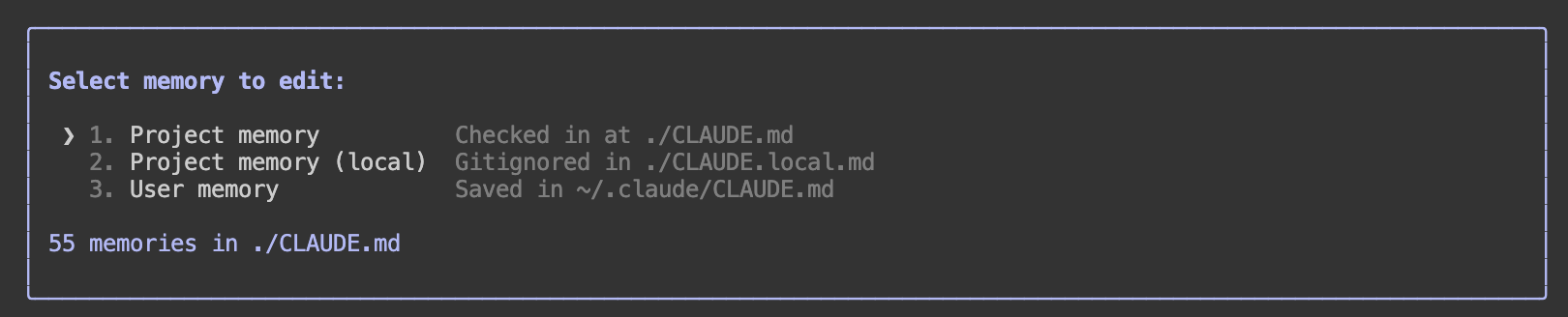
10)把记忆系统用起来,别每个项目重复说偏好
Claude Code 记忆主要有三类:
| 记忆类型 | 文件位置 | 用途说明 | 使用示例 |
|---|---|---|---|
| 项目记忆(共享) | ./CLAUDE.md |
团队共享指令 | 架构约定、编码规范、常用流程 |
| 用户记忆(全局) | ~/.claude/CLAUDE.md |
个人跨项目偏好 | 输出语言、工具习惯、代码风格 |
| 项目记忆(本地) | ./CLAUDE.local.md |
项目个人偏好(旧) | 本地测试数据、沙箱地址 |
会话里可用 /memory 直接编辑:
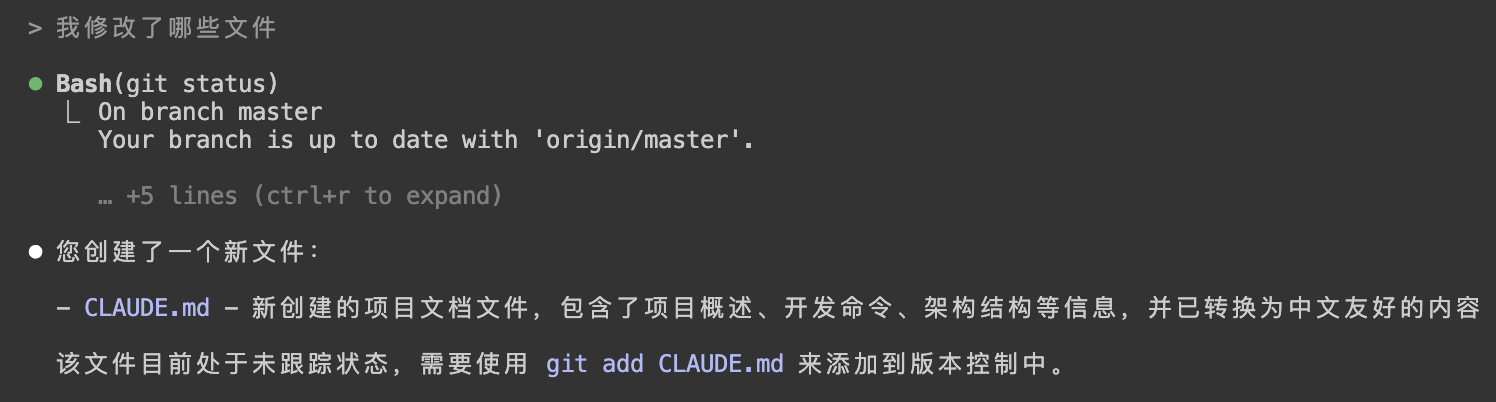
11)让 Claude 用自然语言帮你做 Git 操作
你可以直接说:
- 我改了哪些文件?
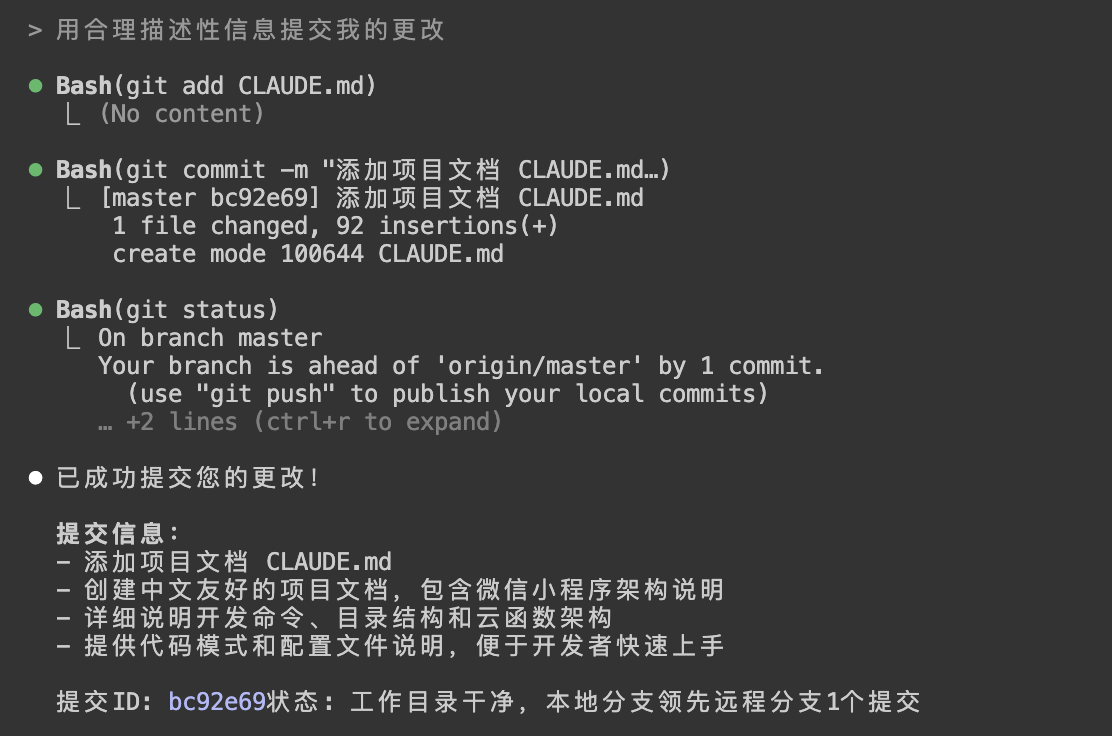
- 用描述性提交信息提交更改;
- 推送当前分支;
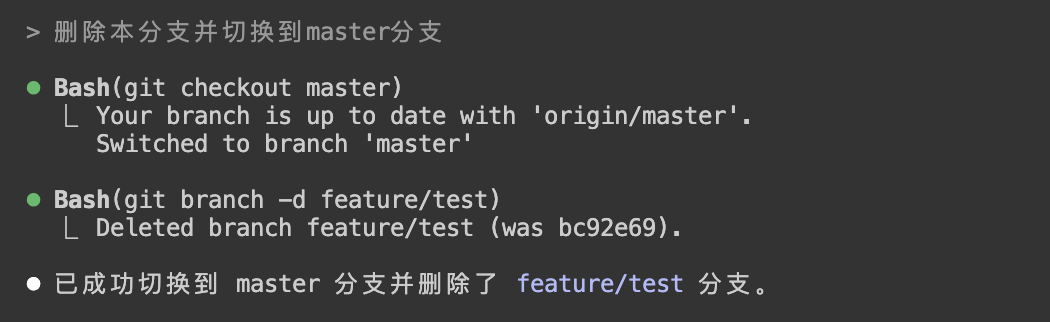
- 创建新分支
feature/test; - 删除当前分支并切回主分支。
对应示例:



12)Linux 命令不会写?让它翻译成命令执行
交互模式下直接说:
> 列出行数最多的前 3 个 .java 文件。
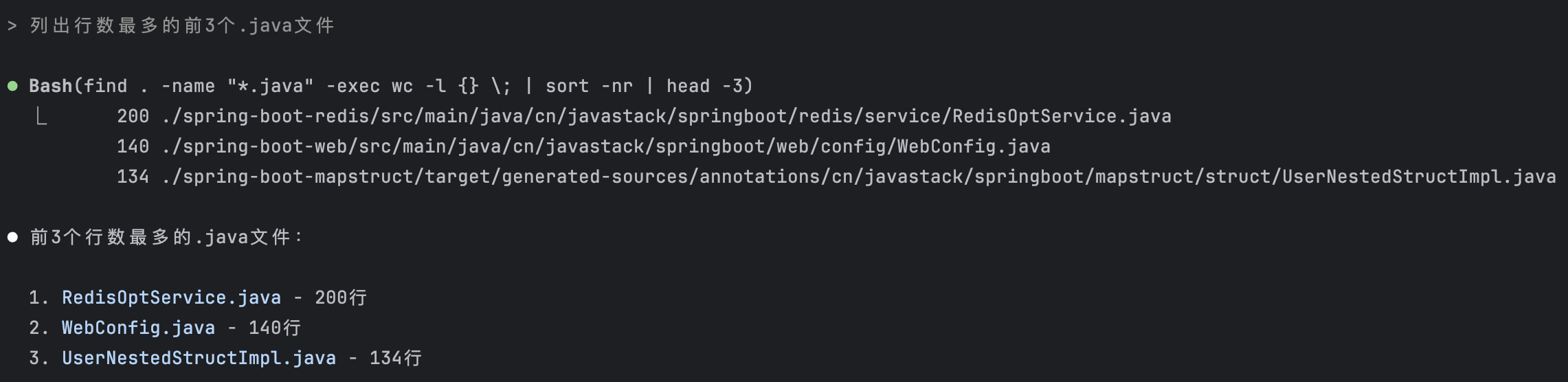
非交互也能一次性执行:
claude -p "列出行数最多的前3个.java文件"

13)模型切换别玄学,按任务选
用 /model 切换模型:

原则很简单:
- 日常开发与迭代:优先 Sonnet;
- 极复杂重构与高难推理:再考虑 Opus。
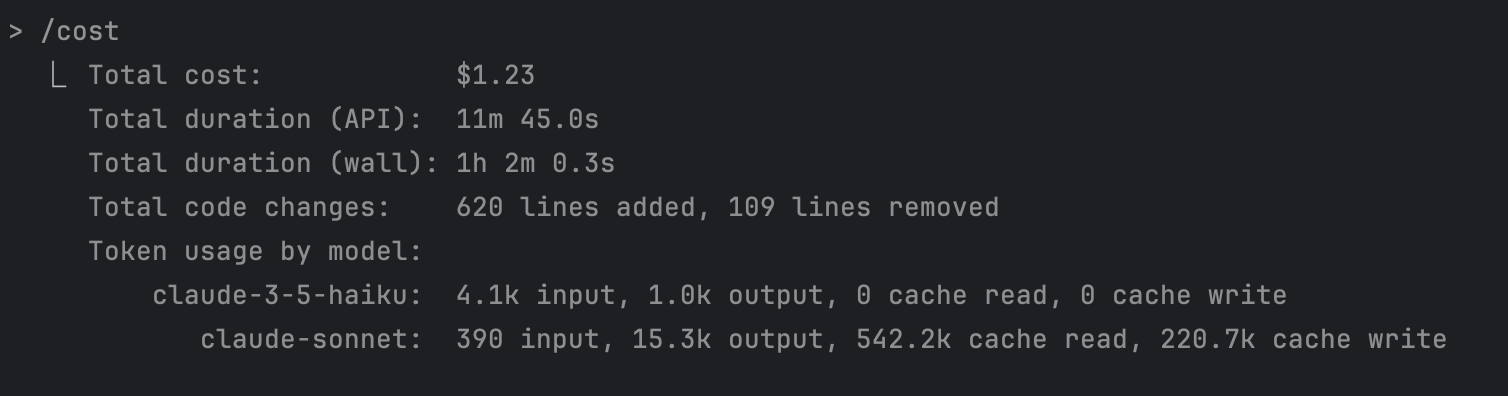
14)成本透明化:/cost + ccusage
先用 /cost 看当前会话消耗:
再配合 ccusage:
sudo npm install -g ccusage
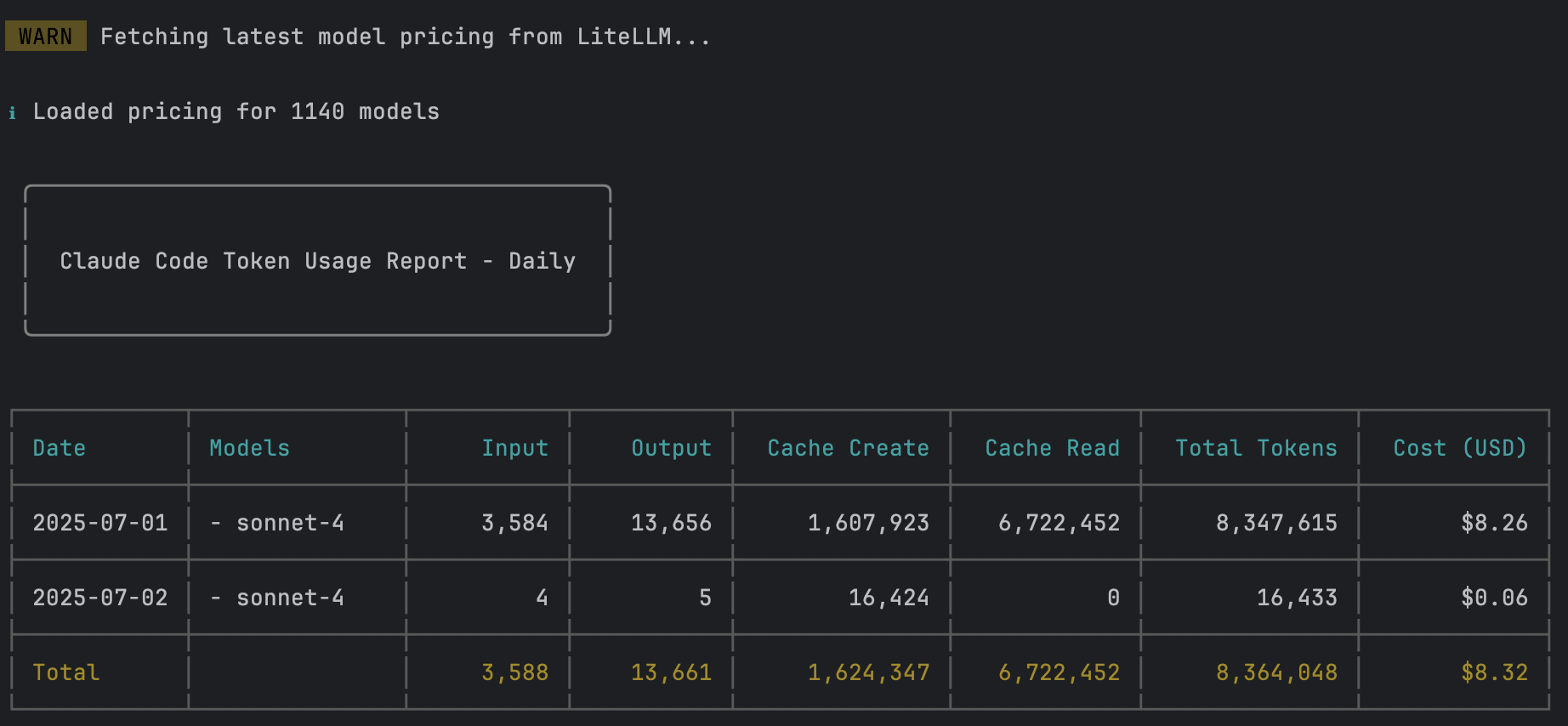
常用命令:
ccusage -s 20250701
ccusage blocks --live
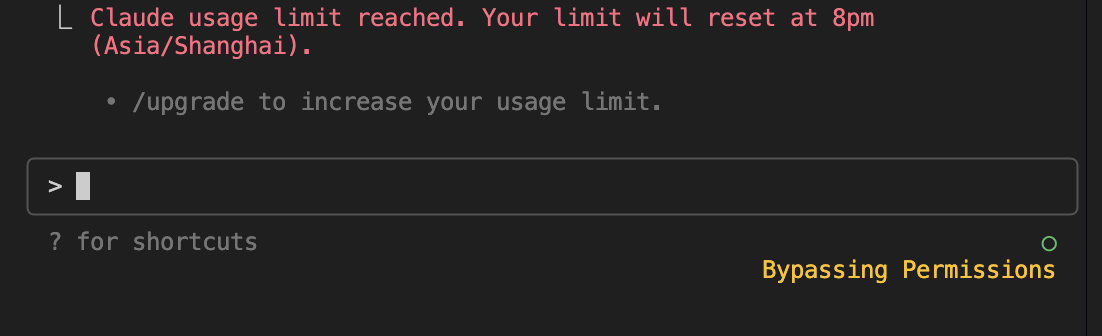
订阅用户虽然不是按 token 即时扣费,但会遇到配额上限:

15)上下文管理:/compact 要主动用
/compact 会清理长历史、保留摘要,是长会话的救命命令:

当右下角上下文比例快见底时,系统也会自动压缩:

建议固定习惯:
- 对话变长就手动
/compact; - 大任务拆分成多轮;
- 定期清理无效上下文。
四、把重复动作产品化:自定义命令(技巧 16)
Claude Code 支持把高频提示词做成命令,语法:
/<prefix>:<command-name> [arguments]
项目级命令目录:.claude/commands
用户级命令目录:~/.claude/commands
比如项目级:
mkdir -p .claude/commands
echo "分析这个项目的性能,并提出三个具体的优化建议。" > .claude/commands/optimize.md
调用:
/project:optimize
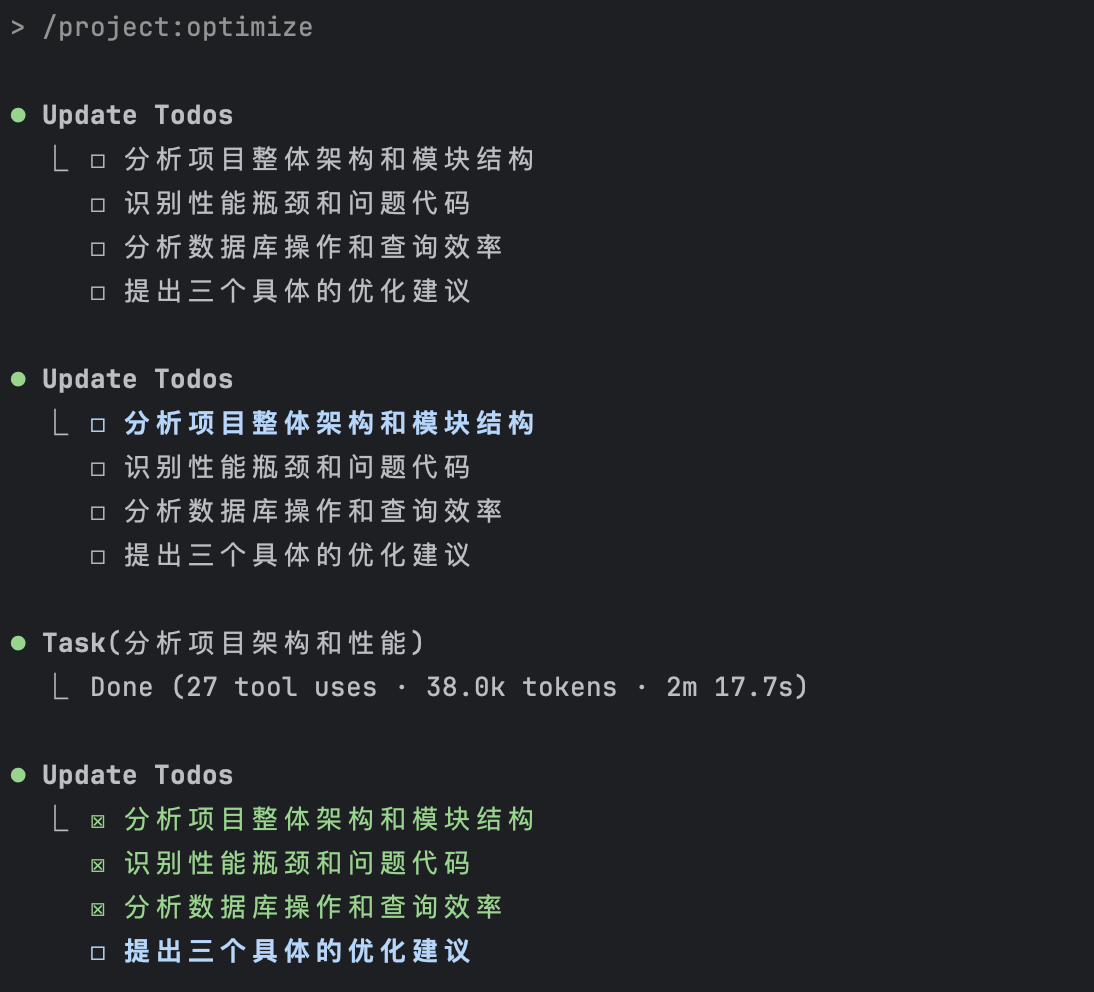
比如用户级:
mkdir -p ~/.claude/commands
echo "用合理描述性信息提交所有变更文件,然后推送到远程仓库。" > ~/.claude/commands/push.md
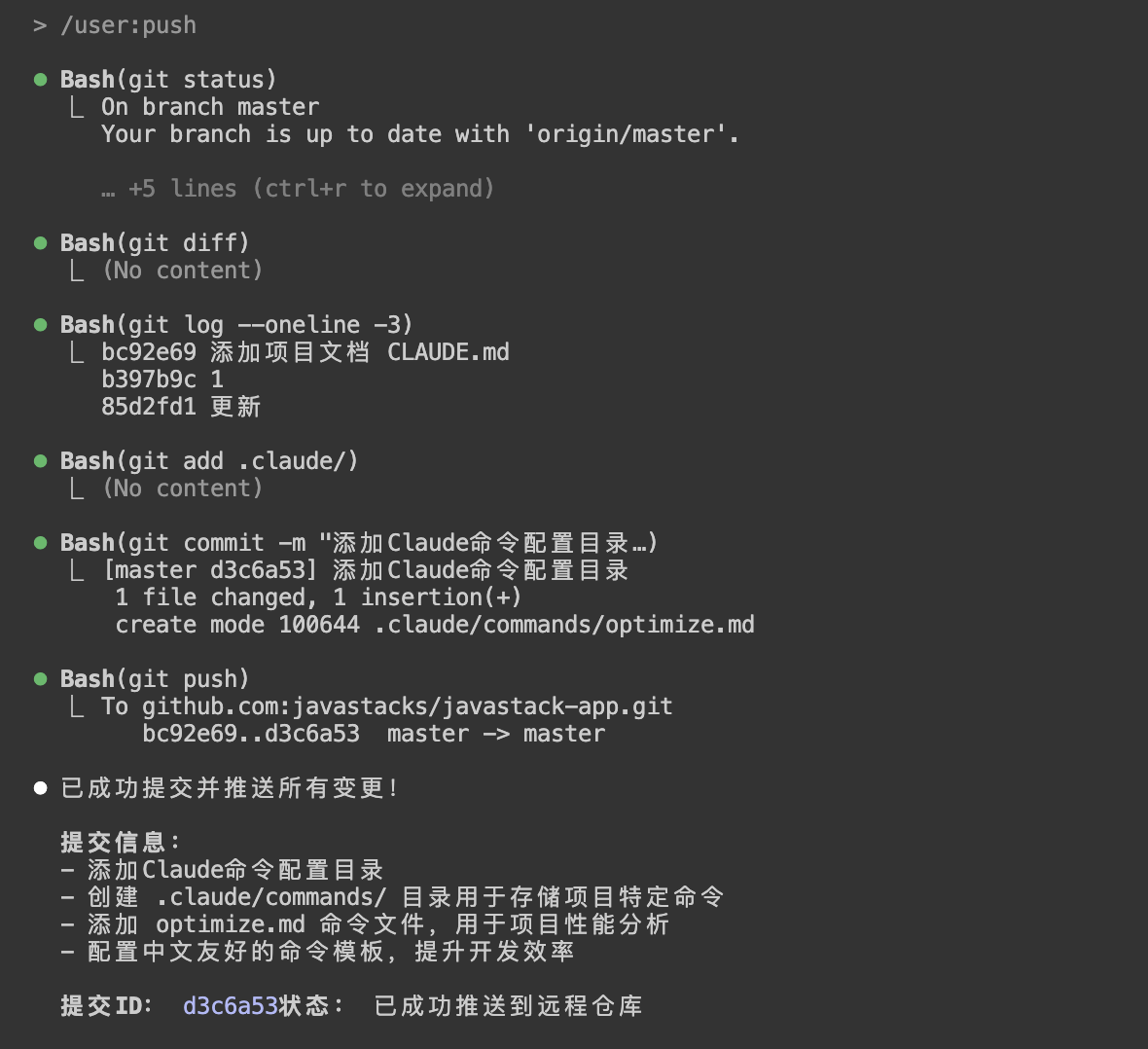
调用:
/user:push
把这些动作沉淀下来后,你的 Claude Code 才会真正从“聊天工具”变成“开发工作流的一部分”。
Claude / Pro / Max / Claude Code 到底怎么选?
如果你刚开始接触,先把产品线理清:
- Claude(网页端):适合问答、写作、文档理解、方案推演。
- Claude Pro($20/月):对话额度更高,适合中轻度日常使用。
- Claude Max 5x($100/月)/ Max 20x($200/月):更适合高频使用 Claude Code 的开发者。
- Claude Code:不是“自动补全插件”,而是终端里的自主 Agent,可读写文件、执行命令、跑测试、改错并迭代。
不过说实话,官方订阅对国内用户不太友好——支付和网络环境都需要自己折腾。如果你想少折腾,可以看看 Code80,通过 API endpoint 方式接入 Claude,日常开发流程会更顺手。详情可见:code.ai80.vip。
常见问题
Q1:提示词到底要写多细?
A:能精确到“触发条件 + 预期行为 + 影响范围”就尽量精确。你说得越具体,它返工越少。
Q2:--dangerously-skip-permissions 可以常开吗?
A:只建议在可信仓库里用。陌生项目、生产目录、含敏感文件的环境,最好保留权限确认。
Q3:什么时候该用 ultrathink?
A:架构设计、复杂重构、疑难问题排查时再开。普通 CRUD、脚手架修改、文案类任务没必要一直开高档位。
Q4:/compact 和 clear 怎么搭配?
A:/compact 适合保留任务摘要继续推进;clear 更像彻底重置。长任务优先 /compact,阶段收尾再 clear。
Q5:国内用户想稳定用 Claude Code,有没有省事方式?
A:如果你不想反复折腾账号和支付,可以用 Code80 这类方式直接接入 Claude 模型,重点放在开发本身。









评论前必须登录!
立即登录 注册