
写在前面
这两个月 AI 编程圈有个很明显的变化:大家已经不太满足于“补全更快一点”“回答更聪明一点”了,真正开始拉开差距的,是谁能把一个很长、很复杂、要反复试错的软件任务一路做完。
所以 Cursor 这次放出来的新东西,值得你认真看一眼。它不是单纯说“我们家模型更强了”,而是同时打了两张牌:一张是性能,一张是成本。更狠的是,它还顺手把自己的训练方法一起讲了出来。
如果你平时就在用 Claude Code、Cursor、Codex 这类工具写代码,那这事跟你不是“行业新闻”的关系,而是很现实的问题:以后你挑 AI 编程工具,到底该看什么?是 benchmark 分数,还是长任务不掉链子的能力?是单次最强,还是长期最划算?
AI 编程的下一轮分水岭:不是更会写,而是更能“持续做”
Cursor 这篇更新里最值得注意的,不是“超过 Opus 4.6”这句口号本身,而是它背后透露出的方向:
- 过去比的是模型会不会写代码;
- 现在比的是模型能不能在终端、仓库、编译、调试、反复修错的长链条里一直不跑偏;
- 再往后,比的就是谁能把这件事做得又强又便宜。
原文一上来就把气氛拉满:Cursor 说自己最新的 Composer 2,不仅能力超过 Claude Opus 4.6,而且价格还不是普通降价,而是直接“脚踝斩”。
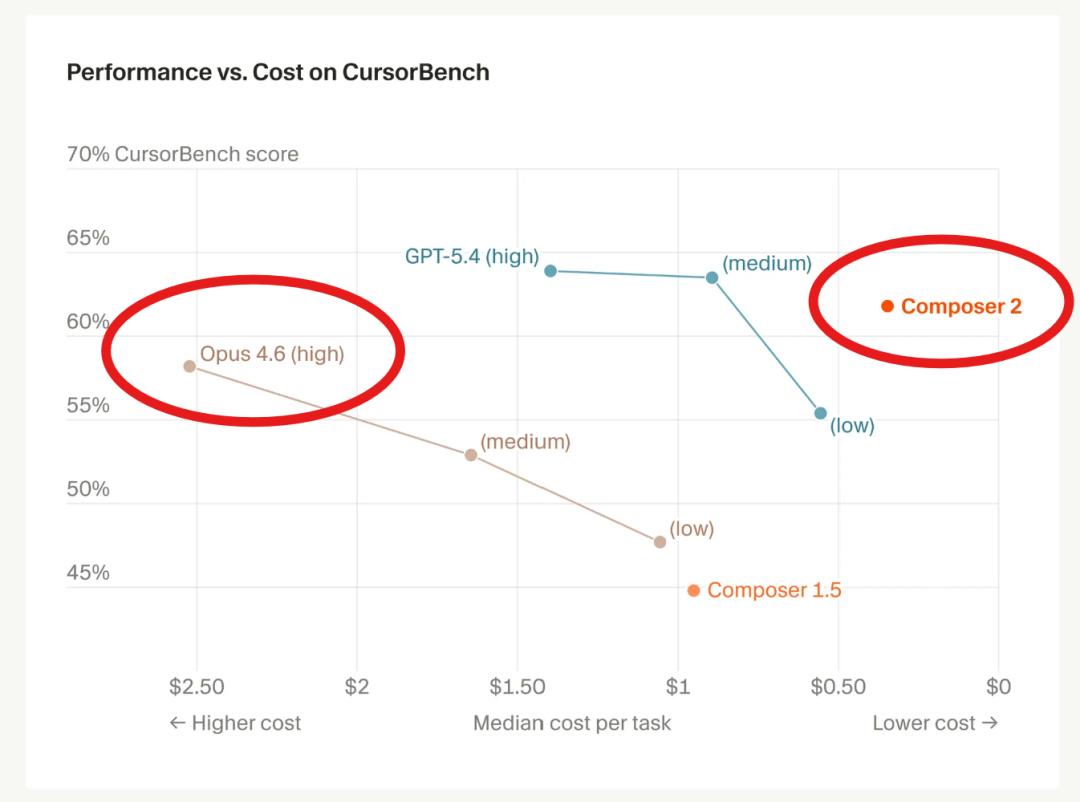
这话为什么会让开发者特别敏感?因为 2026 年以来,整个大模型行业都在面对一个现实:Token 消耗量飙升。尤其 AI 编程场景一火,长上下文、多轮交互、自动调试、终端操作,全都在吃 token。模型公司和云厂商普遍在涨价,谁能在这个时候把价格反着打下来,说明它不是单纯做了市场动作,而是底层能力或者训练方式真有变化。
换句话说,这次不是“又发了个新模型”这么简单,而是 Cursor 在告诉外界:AI 编程模型已经进入既拼上限、又拼单位成本的阶段。
Composer 2 到底强在哪:先看成绩,再看价格
Cursor 先公布的是已经上线的 Composer 2。它给这款模型的定位很直接:专门为编程场景优化,而且核心目标不是一味追求最贵最猛,而是追求“智能与成本的最优组合”。

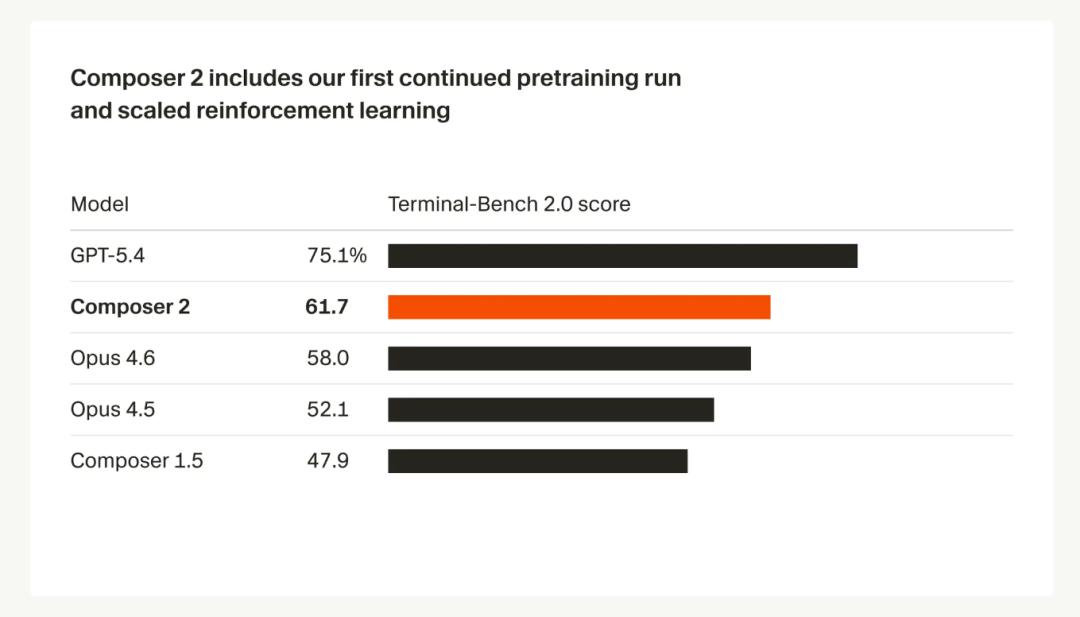
能力层面,Cursor 给出的说法是:Composer 2 在它们衡量的所有基准测试上都有明显提升,重点点名了两个对开发者特别有参考价值的指标:
- Terminal-Bench 2.0:更偏向真实 Agent 在终端里执行操作的能力;
- SWE-bench Multilingual:更接近多语言软件工程任务的修复与实现能力。
这两个 benchmark 为什么值得看?因为它们比传统“会不会补全一段代码”更接近今天 AI 编程工具的真实工作流。你不是只要一个会写函数的模型,你要的是一个能读仓库、跑命令、看报错、改代码、继续迭代的 Agent。
原文里提到,在 Terminal-Bench 2.0 上,Composer 2 的表现已经来到了 GPT-5.4 和 Claude Opus 4.6 之间。
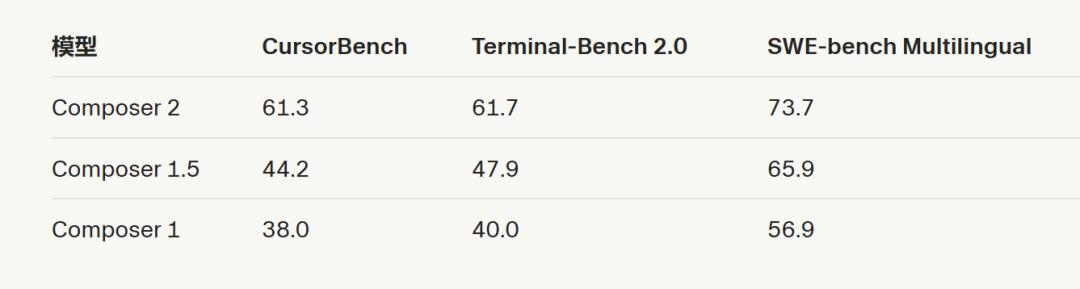
而且 Cursor 还给了一张自家模型演进图,想表达的意思也很明确:Composer 系列不是偶然蹦出来一次,而是在持续往上迭代,速度还越来越快。
接下来就是这次最刺激市场的部分——定价。
标准版 Composer 2 的价格是:
- 输入:0.5 美元 / 百万 tokens
- 输出:2.5 美元 / 百万 tokens
Cursor 的原文措辞很夸张,但意思不难懂:和 Claude Opus 4.6 这类高端模型比,这个价格确实已经不是普通意义上的打折了。
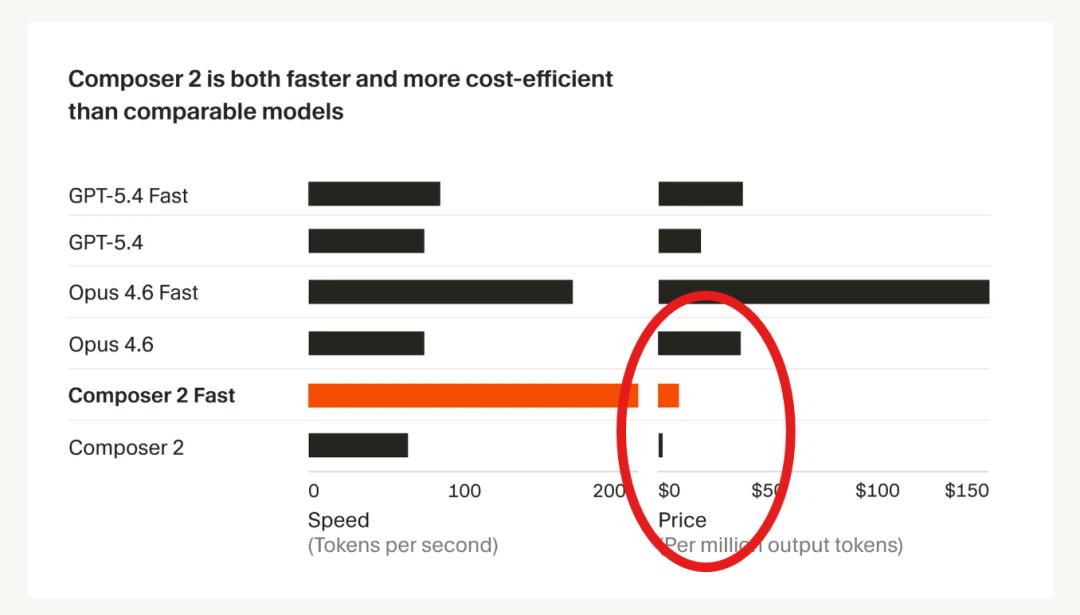
更进一步,Cursor 还给了一个默认更快的变体:Composer 2 Fast。它的智能水平被描述为相近,但响应速度更快,价格是:
- 输入:1.5 美元 / 百万 tokens
- 输出:7.5 美元 / 百万 tokens
这很像什么?很像 AI 编程产品开始做真正意义上的产品分层:
- 如果你要更便宜的大规模调用,用标准版;
- 如果你更看重日常交互速度,用 Fast 版;
- 重点不再只是“最强模型是谁”,而是“什么场景该用哪个档位最划算”。
与此同时,Cursor 也明确说了,自己能把性能和价格同时做到这个位置,靠的不是 prompt 技巧,而是一套新的强化学习方法。

真正的关键,不是“更聪明”,而是学会给长任务做笔记
这次 Cursor 最值得开发者研究的,其实是第二部分:它把自己的一种新训练思路公开讲出来了。你可以把它理解成——让模型学会在超长任务中给自己做阶段性笔记,然后带着这些笔记继续往下干。

这个思路为什么重要?因为今天大多数 AI 编程助手,在短任务里已经都不算差了。真正一上强度,问题就来了:
- 任务跨度太长;
- 中间步骤太多;
- 代码、日志、编译结果、计划状态混在一起;
- 上下文窗口再大,也总有装不下的时候。
于是行业里常见的做法,大致有三类:
- 普通摘要:聊到一定长度后,做一次总结再继续;
- 滑动窗口:直接把更早的上下文丢掉;
- 潜在空间压缩:把上下文压成向量,而不是保留成文本。
这些方法都不是没用,但都有同一个隐患:你在压缩的时候,可能把真正关键的信息也一起弄丢了。 一旦丢的是“为什么刚才这么改”“下一步原计划是什么”“这个 bug 试过哪些解法”,模型后面就很容易越做越偏。
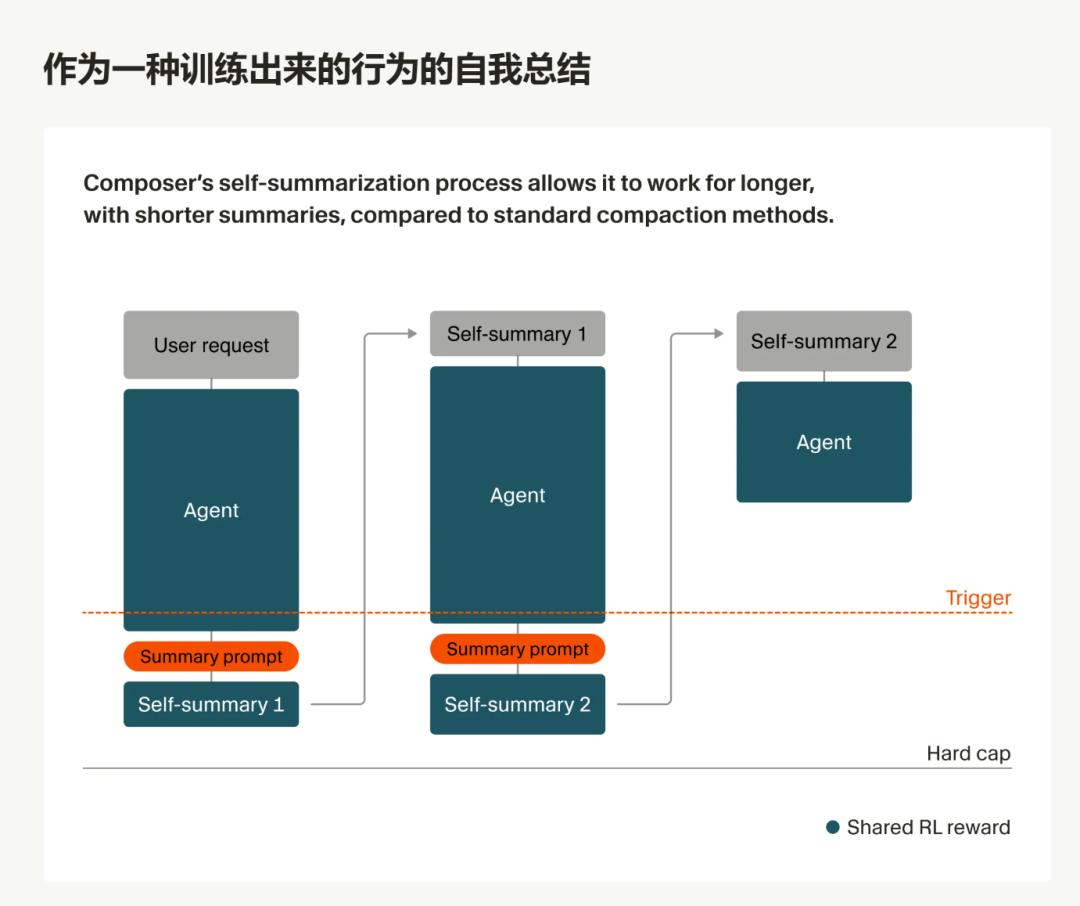
Cursor 的做法是,把“总结能力”本身也纳入训练目标。不是被动压缩,而是主动让模型在合适的时机停下来,给自己写一段能继续接力的总结。
原文给出的流程大致是:
- Composer 先持续处理当前任务;
- 到达固定 token 触发点后,插入一个合成查询,让模型总结当前上下文;
- 给模型一小段草稿思考空间,组织出最好的阶段总结;
- 后续再拿这份压缩后的上下文继续做,里面不仅有总结,还包含规划状态、剩余任务、总结次数等执行状态。
这件事最关键的一点在于:它不是临时技巧,而是训练出来的能力。
在强化学习阶段,好的总结会带来更高的任务完成率,于是得到更高奖励;如果总结把关键信息丢了,后面的任务更容易失败,就会被惩罚。久而久之,模型就会学会一件事:到底什么信息必须留下,什么信息可以丢。
这很像一个成熟工程师写交接文档。不是把所有聊天记录一股脑贴上去,而是知道哪几条决策、哪几个坑、哪几个剩余事项,才是后面继续干活真正需要的。
这种方法到底值不值:Cursor 给了两个很有说服力的例子
第一个例子,是它拿传统摘要法和 self-summary 机制做对比。
按照原文说法,在一组高难度软件工程任务里,传统摘要法为了让模型继续做事,往往需要一大段专门的摘要提示词,而且压缩结果本身仍然很长,平均要 5000+ tokens。但 Composer 这套方法里,触发总结的提示很简单,甚至可以只是“Please summarize the conversation”,最终压缩结果平均只有 1000 tokens 左右。
结果是什么?同样的任务里,它的 token 消耗大约只有传统方案的 1/5,而且压缩引入的错误还能再降大约 50%。
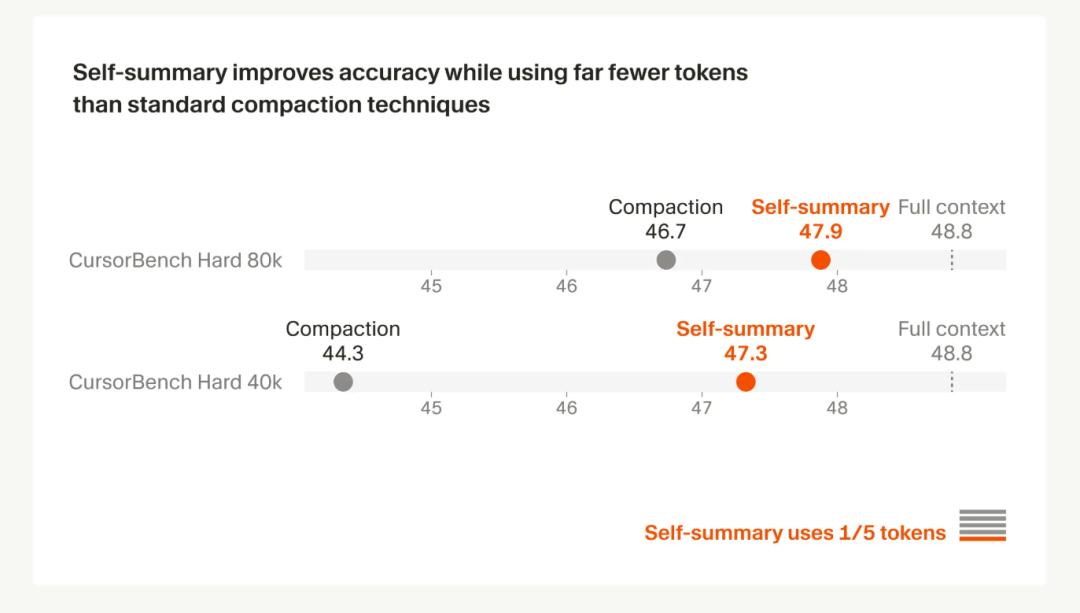
这个结果的价值很直接:
- 压得更短,意味着更便宜;
- 保留的信息更关键,意味着更稳;
- 同时做到这两点,才有机会在真实开发场景里把长任务跑完。
第二个例子更狠。Cursor 拿了一道很经典、也非常折磨 Agent 的任务来测试:把 Doom 跑在 MIPS 架构上。
这类任务为什么难?因为它不是“写一个函数”这么简单,而是要你持续读代码、改代码、编译、调试、看运行结果,再继续修。它天然就会把上下文拉得很长,中间还充满试错。

按照 Cursor 的说法,Composer 在 170 轮交互 后找到了精确解法,而且在这个过程中,把 10 万+ tokens 的历史上下文持续压缩到大约 1000 tokens 级别,还能把关键信息一路传下去。
这件事对 AI 编程工具意味着什么?意味着未来真正厉害的 Agent,可能不是“第一轮回答最惊艳”的那个,而是第 120 轮还记得自己为什么这么改、下一步该去哪里验证的那个。
Cursor 后面还提到,Composer 3 的消息也已经开始往外放了,说明它们并不想把 Composer 当成一次性的功能点,而是当成一条模型产品线在推进。
同时,Cursor CEO 也给出了一个挺有代表性的判断:Cursor 这种公司,已经很难简单归类成“纯应用公司”或者“纯模型公司”了。

这句话其实挺能代表当下行业状态。AI 编程产品正在变成一个新的混合体:上面是 IDE、Agent、工作流,下面是模型、训练方法、推理与成本控制。以后你看到的头部工具,越来越可能既做产品,也做模型。
这波消息对开发者真正有啥影响?
如果你平时只是把 AI 当成问答工具,这条新闻看完可能就是一句“哦,Cursor 又发模型了”。
但如果你已经开始用 AI 真正写代码、改项目、跑终端、做多文件修改,那这件事的含义很大。
1)Benchmark 以后不能只看单点成绩
Terminal-Bench、SWE-bench 这类指标依然重要,但更重要的是:模型在长链条任务里会不会掉线、会不会遗忘、会不会因为压缩上下文而把关键状态丢掉。
2)成本会越来越成为核心竞争力
AI 编程一旦进入高频使用阶段,价格不是锦上添花,而是直接决定你能不能长期开着用。一个模型哪怕只比别人便宜一点,乘上每天的大量终端操作、多轮交互、自动修 bug,最后都是实打实的差距。何况 Cursor 这次不是便宜一点点。
3)“会总结自己”可能会成为下一代 Agent 的标配
过去我们强调上下文窗口越大越好,现在看,光大还不够,关键是怎么在长任务里保真地压缩。 谁能把“阶段性自我总结”做成稳定能力,谁就更有机会在真实软件工程里赢下来。
Claude Code 到底是什么?为什么大家会拿它当参照物?
这次 Cursor 之所以会引发这么大讨论,一个重要原因就是它拿来对比的对象里,有 Claude Opus 4.6。而在开发者圈里,很多人真正日常在意的,并不是某个抽象模型名,而是:它在 Claude Code 这种 Agent 形态里到底能不能打。
Claude Code 不是传统意义上的代码补全插件,它更像一个终端里的自主编程 Agent。你给它一个任务,它能自己去读文件、执行命令、跨文件修改、跑测试、看错误、继续修,直到把任务推进下去。
这类工具真正吃模型能力的地方,不在“会不会写一段函数”,而在:
- 能不能理解整个代码库;
- 能不能在多轮交互里保持方向;
- 能不能处理终端和工程环境里的真实噪音;
- 能不能把复杂任务拆解后一步步做完。
也正因为这样,Cursor 这次强调“长任务压缩”和“self-summary 训练”,才会让开发者特别关注。因为它瞄准的,正是 Claude Code 这类产品最核心的战场。
官方订阅这边,如果你想高频使用 Claude Code,一般会关注 Anthropic 的 Max 档位或 API 方案。对重度开发者来说,这类官方能力当然最直接,但说实话,国内用户在支付和网络环境上一直不算轻松。如果你嫌这些环节太折腾,想找个更省事的方式,可以看看 Code80,用 endpoint 方式接入 Claude,日常在本地开发环境里会顺手很多。详情可以到官网了解:code.ai80.vip
常见问题
Q1:Composer 2 这次最值得关注的到底是什么?
A:不是单一 benchmark 分数,而是它把“长任务里的上下文压缩”单独拎出来做成了训练能力。这对真实软件工程场景的意义,比普通问答模型提升要大得多。
Q2:self-summary 和普通摘要有什么区别?
A:普通摘要更像外部给模型做压缩,self-summary 则是把“什么该保留、什么能丢”训练进模型本身。前者能用,后者更像能力内化。
Q3:为什么 Terminal-Bench 2.0 这种指标越来越重要?
A:因为 AI 编程工具正在从“写几行代码”变成“在终端里持续完成任务”。谁能稳定处理命令、报错、调试、回归,谁才更接近真正的 Agent。
Q4:Cursor 这次是不是说明 Claude 系模型不行了?
A:还不能这么下结论。一个模型在线上产品里的实际体验,除了基座能力,还和工具形态、上下文工程、Agent 编排、价格策略都有关系。但可以确定的是,竞争已经从“谁更会答题”升级成“谁更适合长期干活”。
Q5:国内如果想更稳定地用 Claude Code,有没有省事一点的方式?
A:如果你不想自己反复折腾支付和网络,可以通过 Code80 这类方式更方便地接入 Claude,把精力放回开发本身。
评论前必须登录!
立即登录 注册