写在前面
这几个月看模型更新,如果你还只盯着“谁跑分高”“谁聊天更像人”,其实已经有点落后了。现在真正拉开差距的,不再只是单轮问答,而是模型能不能把一整段工作流接住:搜资料、整理表格、写代码、调界面、生成报告、甚至把结果发出去。
这也是为什么最近很多人在看所谓的“龙虾榜”——它测的不是你答题像不像标准答案,而是你能不能把一件完整的事做完。任务一长、步骤一多、工具一接入,模型之间的差距就开始真正暴露出来。
而这次 MiniMax M2.7 最有意思的地方,不是又发了个新模型,而是它在真实 Agent 场景里给人的感觉已经不太像“聊天模型”,更像“能接活的执行体”了。问题就变成了:它到底强在哪?哪些场景是真的能打?又有哪些地方还没到可以闭眼上的程度?
现在卷的已经不是回答问题,而是能不能把整件事做完
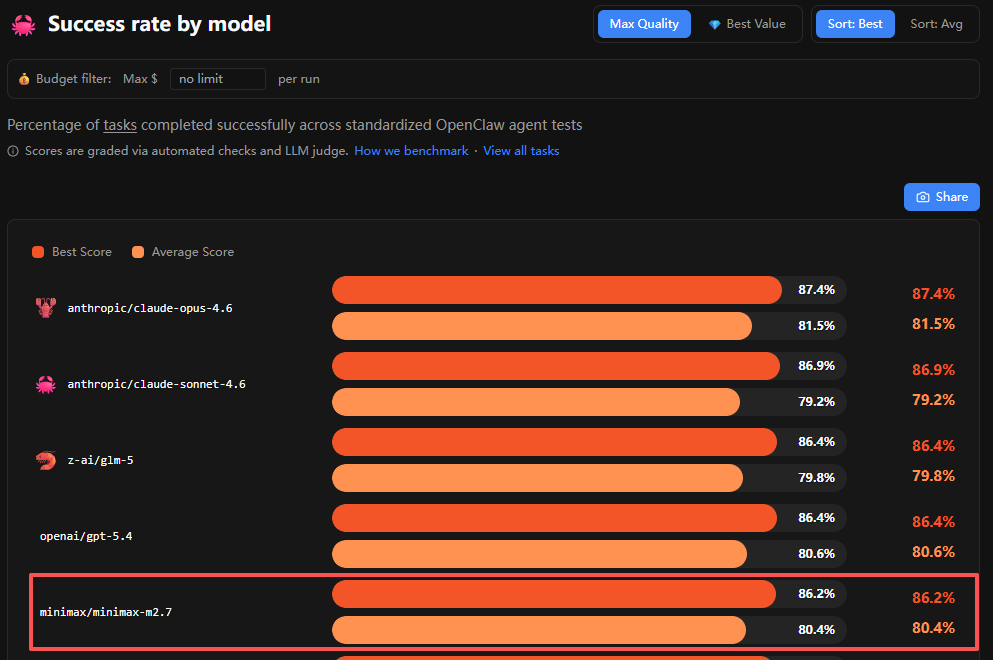
先看一个最抓人的信息点:按原文里的描述,MiniMax M2.7 在实时更新的 PinchBench 上已经来到全球第四。这个榜单之所以被反复提起,是因为它看的是 Agent 任务成功率——不是做题,而是执行。
这件事对开发者其实很重要。
因为你今天真正想交给 AI 的,往往都不是“帮我补一行代码”这么简单,而是:
- 去网页上搜信息
- 把信息整理进表格
- 再做成图表或页面
- 再把结果投递到飞书、邮件或其他工具里
- 或者直接写出一个能运行的前端/脚本/网站
一旦任务变成这种链条式结构,模型如果只是会续写、不会规划,不会调工具,不会在长上下文里稳定执行,那体验就会立刻塌下来。
所以这次 M2.7 让人觉得值得看,不是因为它“又强了一点”,而是因为它在多个不同类型的长任务里,都开始显出那种“能把活做到底”的感觉。
这次实测到底测了什么:六个场景,基本把 Agent 能力拆开了
原文这次没有只做单一 demo,而是直接上了 6 类任务,覆盖了 Agent 时代最关键的几种能力:
- 多步骤龙虾任务
- 自动化视频生成
- Claude Code 里的编程任务
- 前端页面生成
- 调用 skills 搭网站
- 办公场景下的报告、图表、PPT 联动产出
这种测法比单纯 benchmark 更有参考价值。因为你能直接看到:模型到底是只会在一类场景里偶尔惊艳一下,还是在“执行链路”这件事上整体变强了。
1)龙虾任务:搜索、整理、制图、发飞书,一条链路直接跑通
第一个案例本身就很像现实工作流。
任务要求是去豆瓣找最近热门电影,结合热度、评分和上映时间综合筛选 10 部,整理成 Excel,再根据表格做一个可视化 HTML,最后把 Excel 和 HTML 一并发到飞书。
这不是一个单点能力测试,而是一条完整流水线:
- 联网检索
- 理解筛选条件
- 结构化整理数据
- 生成表格
- 生成可视化页面
- 把文件投递到指定工具
原文给出的结论是:M2.7 一次过,直接交付了 Excel 和 HTML。
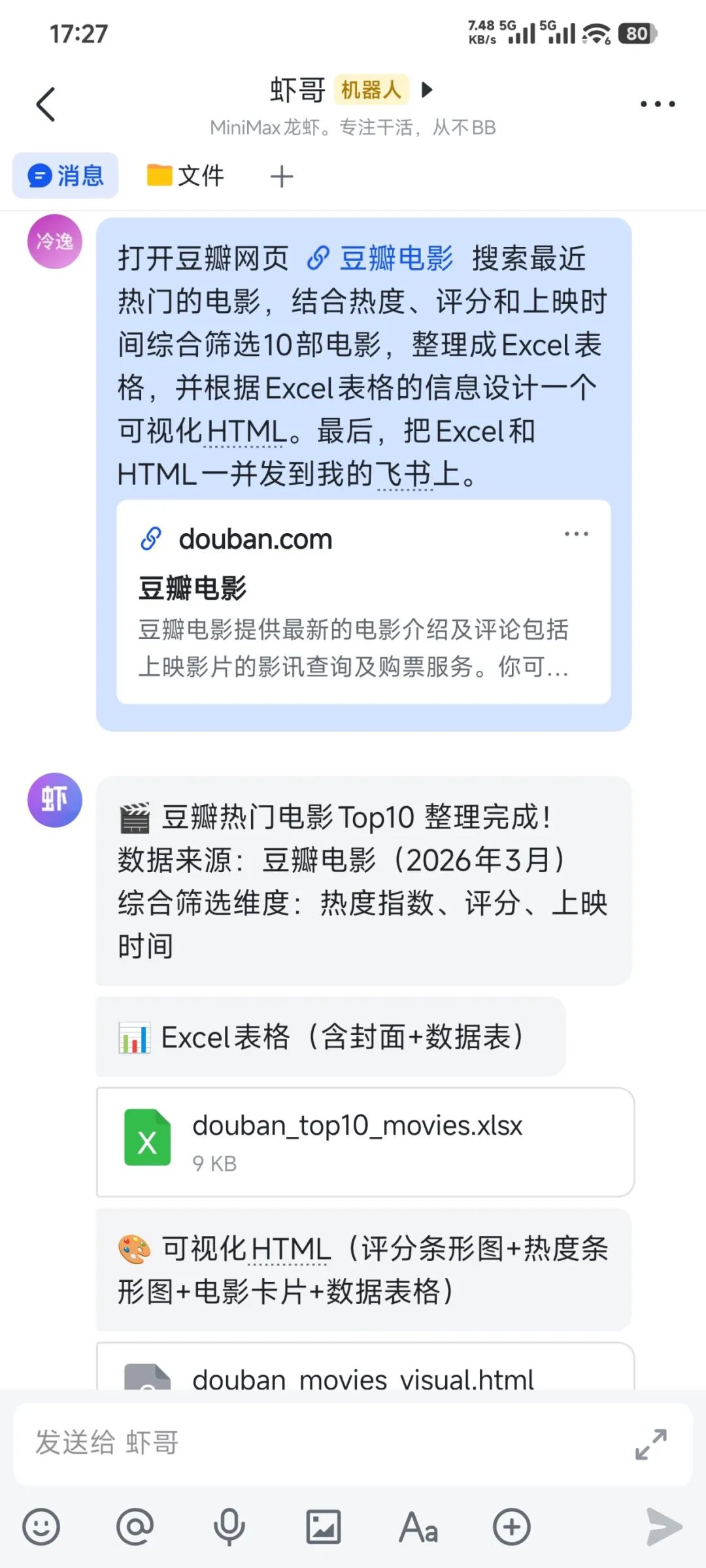
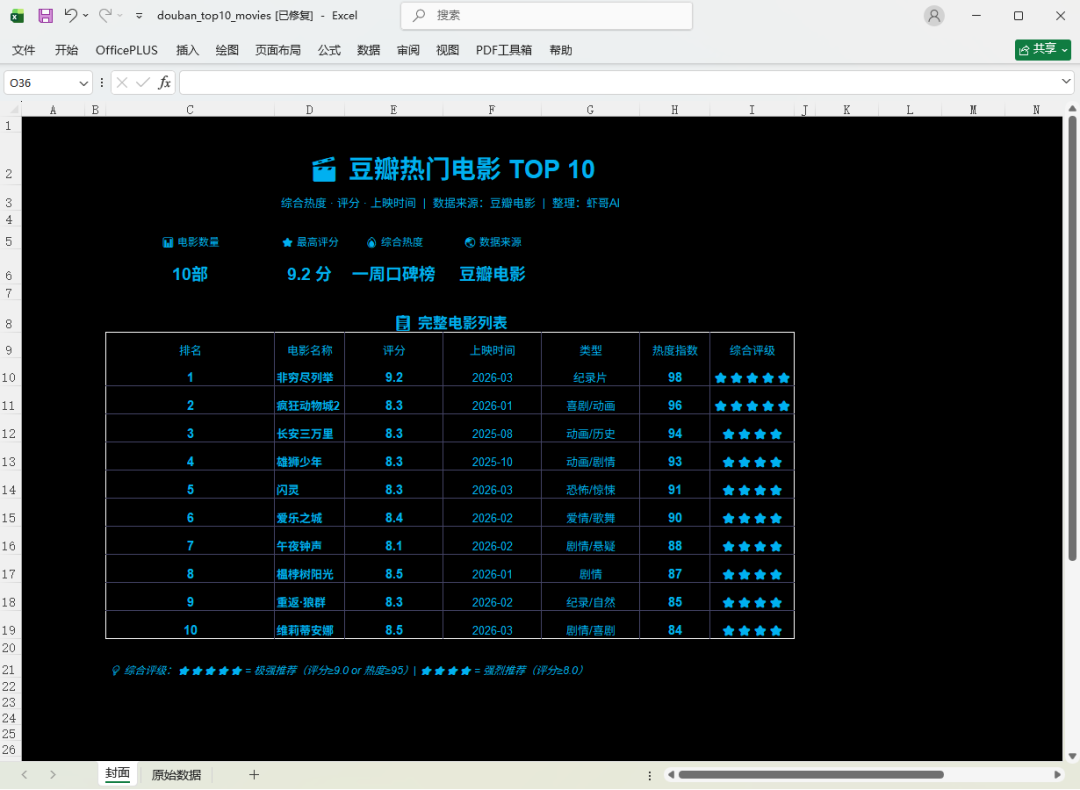
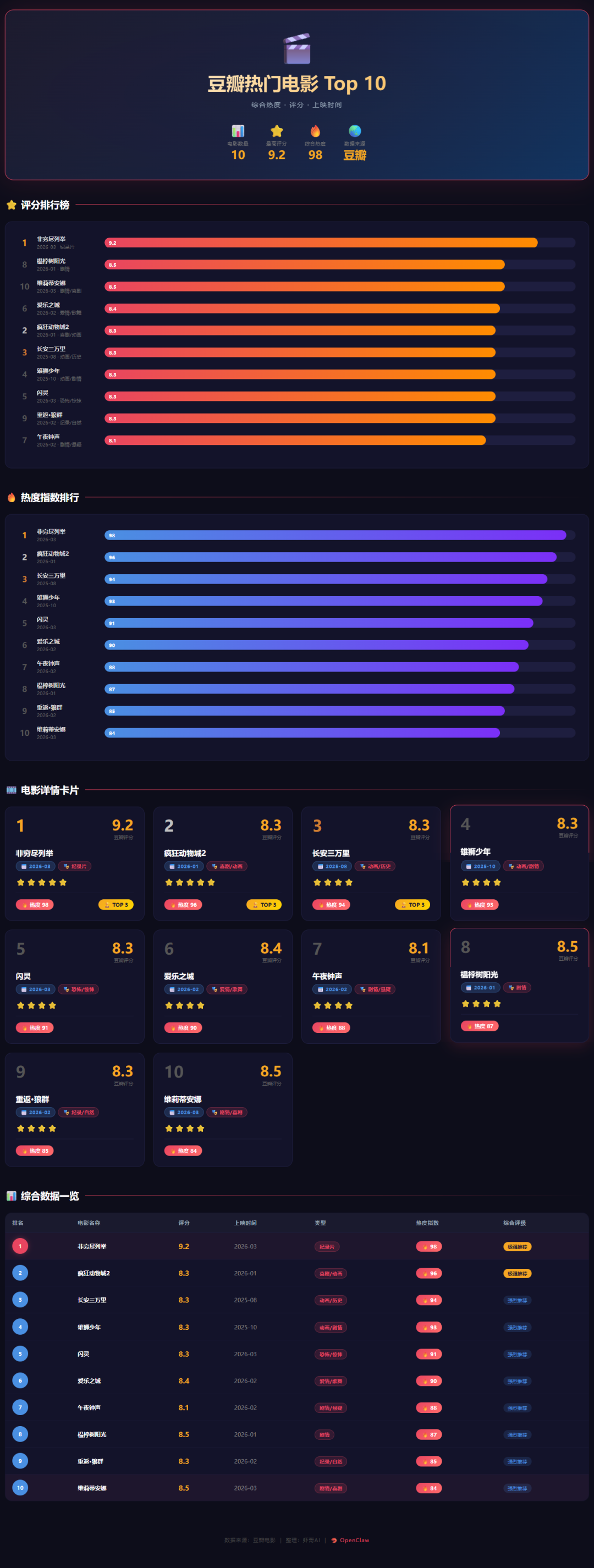
更值得注意的不是“做出来了”,而是它在这类长任务里没有中途掉链子。因为这种任务最常见的失败方式不是代码报错,而是执行过程中忘步骤、漏条件、结果格式不统一,最后给你一堆半成品。
从原文展示看,M2.7 在这个案例里给出的结果已经接近“可直接交付”,这说明它在长指令理解、阶段切换和工具串联上,确实已经到了一个比普通聊天模型更像 Agent 的层级。
2)自动做视频:不只是生成片段,而是走完整工作流
第二个案例更狠,直接让它用 libtv-skills 生成一个 40 秒短漫剧《像素荒原》。给的要求并不轻:世界观、视觉风格、剧情线、隐喻主题,全都写得很具体,而且目标不是生成几段素材,而是完整视频。
原文给出的结果是,这条工作流从剧本、分镜图、分镜视频到最后合成,都是由 MiniMax M2.7 驱动完成的。
这里面最关键的不是“视频看起来还不错”,而是它完成的是多阶段创意工作流:
- 理解抽象主题
- 把主题拆成可执行分镜
- 调用对应能力生成内容
- 最终合成为一个完整产物
也就是说,它已经不只是“根据一句话给你吐一个结果”,而是在把一条需要多次中间转换的流水线接起来。
当然,原文也提了一个很实在的细节:如果你不强制调用对应 skill,系统可能只会生成镜头片段,而不是完整视频。这恰恰说明一个现实问题——模型能力是一回事,工作流编排仍然同样重要。
3)编程任务:在 Claude Code 里测 3D,空间理解和修 bug 能力都过了一轮
接下来几项测试被放进了 Claude Code,这部分对开发者更有参考价值。
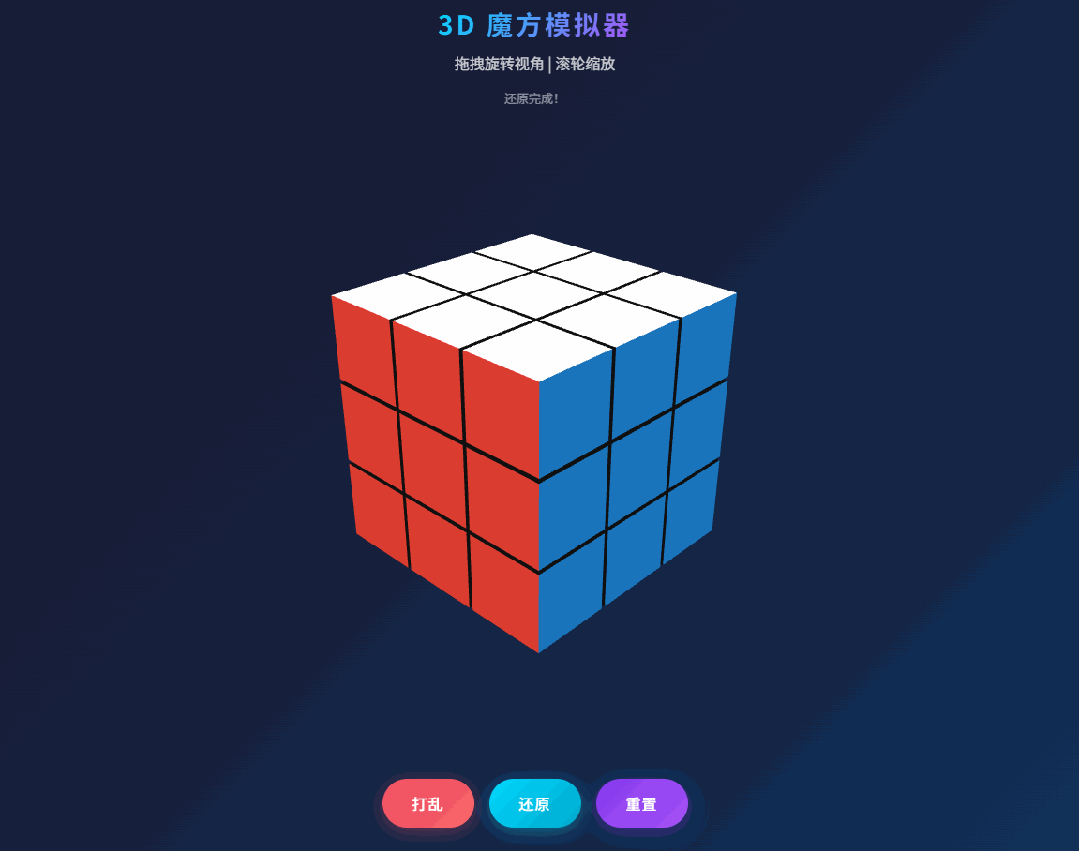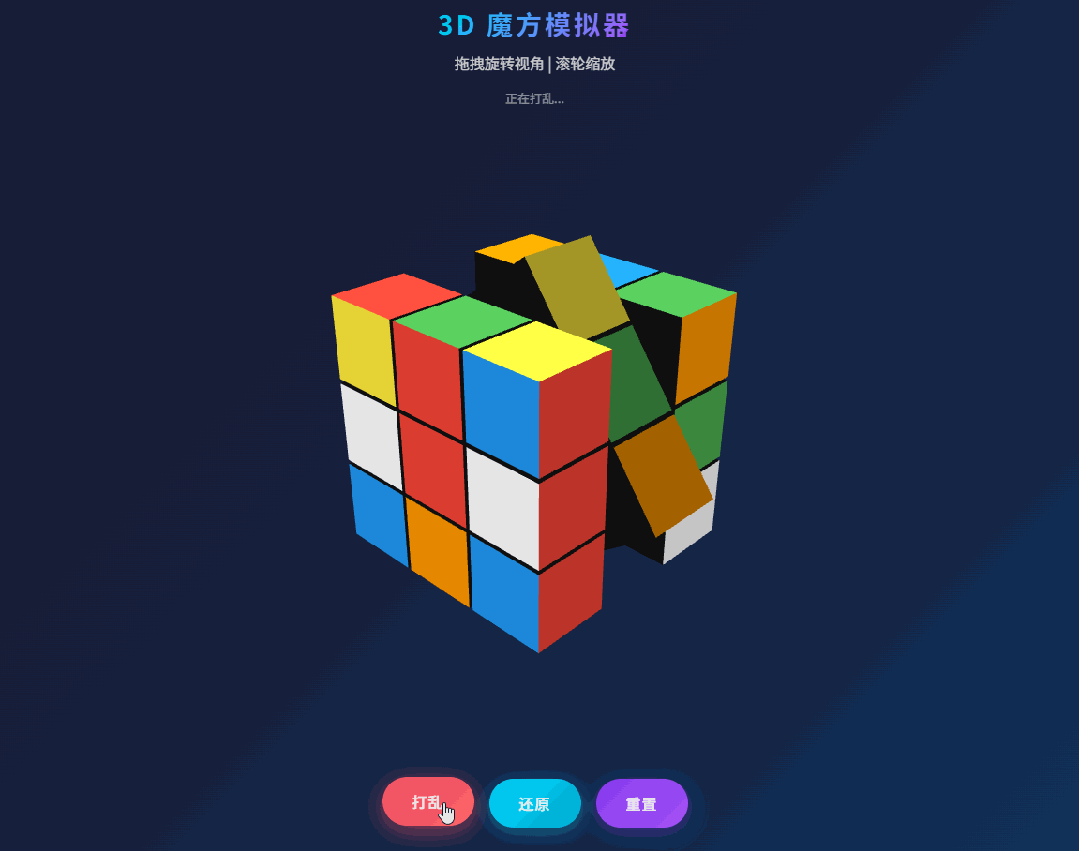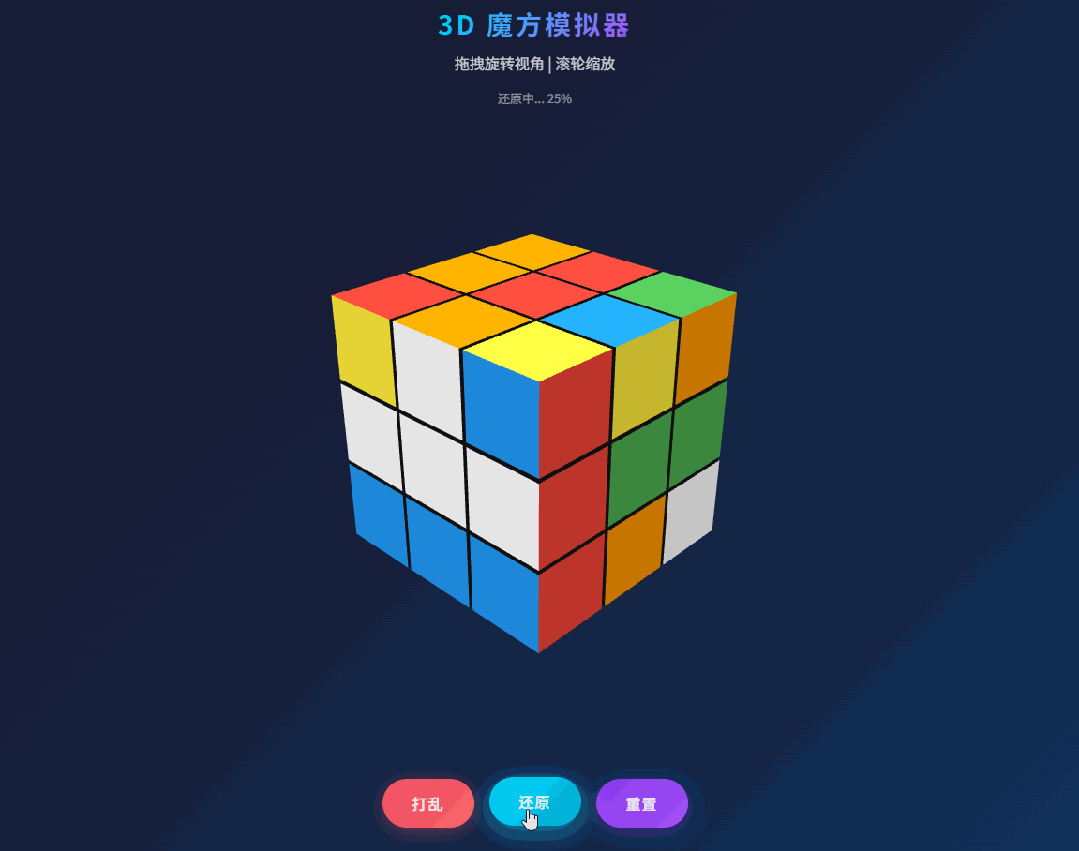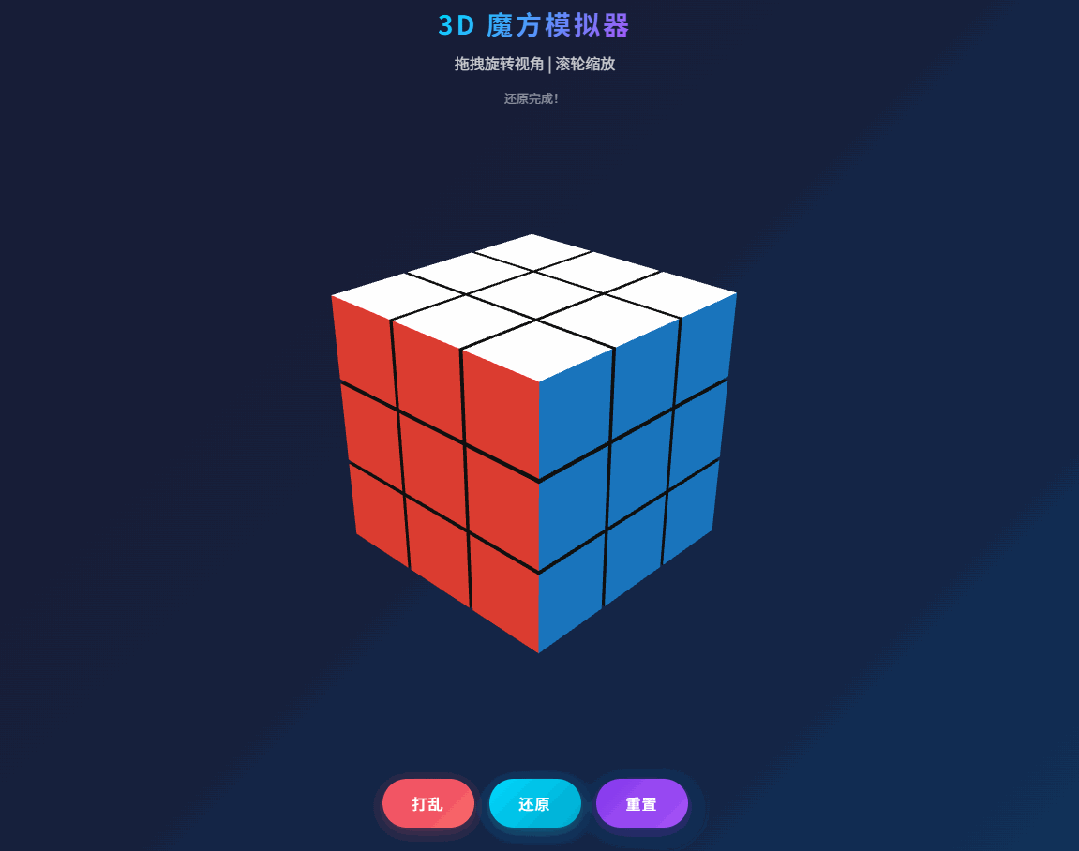
第一个编程 case 是经典 3D Rubik’s Cube:要求创建一个单文件 HTML,用 Three.js 实现一个功能完备的 3D 魔方模拟程序,并且能自动完成还原。
这个任务很适合测模型两个东西:
- 空间与结构理解能力
- 出错之后的修复效率
原文的观察很真实:第一版并不是完美 one shot,在打乱和还原动画过程中,出现了部分方块颜色丢失的问题,本质是位置与颜色状态没有正确同步。简单反馈之后,第二版就把问题修掉了。
这类 case 之所以值得看,是因为它不像 CRUD 页面那样容错高。3D 场景一旦状态管理有点问题,视觉错误会特别明显。M2.7 在这里表现出来的,不只是“能写个看起来像样的 demo”,而是出了 bug 之后,它能快速收敛到正确版本。
4)前端任务:审美在线,但视觉理解还是短板
再往下是一个更偏产品展示的前端任务:给 AI 鼠标「小沃」设计产品宣传页。

原文给出的评价很直接:VI 和配色都不错,页面观感是在线的。
这一点其实挺重要。因为现在很多模型能把页面“做出来”,但做出来和“看起来像能上线的东西”中间差得非常远。配色、视觉层级、留白、信息组织,只要有一项不对,成品就会立刻显出浓重的 AI 味。
不过作者也点出了当前短板:M2.7 还不具备视觉理解能力。如果未来这块补上,它在设计稿还原、视觉对齐、图像驱动改版这类场景里,应用范围会比现在大得多。
5)调用 skills 做网站:One shot 能成,但外部内容读取还有限制
第五个测试更贴近现在很多开发者在玩的方向:不只是让模型直接写代码,而是让它调 skills,去构造一个更复杂的网站工作流。
任务是调用 Knowledge Site Creator Skills,为“Token”做一个知识学习网站,要求既严谨又有趣,还要有高级审美。
原文这里的结论是,这次 one shot 的效果不错,排版和配色都很在线。但问题也同样明显:它似乎不能直接读取公众号 URL,文章内容还是需要手动喂给 Claude Code。
这个细节非常值得记一下。因为很多人现在对 Agent 的预期已经拉到“给个链接它自己全搞定”,但现实是:
- 模型能力是一层
- 工具权限是一层
- 外部内容可访问性又是一层
你看到一个 Agent 工作流能不能闭环,往往不只是看模型本身,还要看它站在什么运行环境里、拿到了哪些能力边界。
6)办公任务:财务模型、研报、PPT 三件套一起做
最后一类测试是最接近企业办公场景的:基于腾讯 2025 年财报信息,读取多个研报,建立营收模型,设计假设,生成 PPT、Word 研究报告和 Excel 图表。
这类任务真正难的地方不是“会不会写几段分析”,而是:
- 数据搜集是否准确
- 结构化整理是否完整
- 不同交付物之间是否一致
- 长上下文里会不会出现幻觉
原文给出的观察相当强:Excel 财务模型结构完整,收入、盈利、核心业务、估值这些部分都覆盖了;Word 报告 23 页、近万字,抽查数据准确;PPT 排版与 UI 质量也明显高于“草台拼接感”。

作者也没有一味吹,还是指出了问题:复杂多坐标图表在 Python 绘图阶段没有完全呈现出来,Word 的字体和排版也还有小毛病。
但这恰恰是这类 Agent 最现实的价值所在:它未必一次性把最后 5% 的精修也替你做完,但它已经把最耗时间、最容易烦躁、最适合自动化的 80% 搞定了。对于分析、咨询、投研、运营这类岗位,这种价值其实非常直接。
这篇实测真正说明的,不是 MiniMax M2.7 会做多少事,而是 Agent 工作流开始变实用了
把这 6 个案例放一起看,M2.7 展示出来的核心能力大概有四类:
1. 长任务指令遵循更稳了
多步骤任务最怕中途偏题、漏步骤、忘上下文。原文里无论是龙虾任务、视频生成,还是办公三件套,M2.7 最突出的优点都是能把一长串需求维持住,不轻易跑偏。
2. 工具调用开始有“工作感”了
不是单纯会 function calling,而是真的能围绕一个目标去组织多个工具。搜、写、算、画、导出、发送,这种链路一旦能顺起来,模型就不再只是助手,而是开始像执行者。
3. 编程质量已经能进入开发者日常流程
在 Claude Code 里的几个任务说明,M2.7 至少已经进入“能拿来真干活”的区间。不是每次 one shot 完美,但能在反馈后快速修正,并且前端、3D、网站生成这些横向场景都能接住。
4. 办公场景的交付可信度明显提高
很多人对 AI 做办公任务的担心,本质上都是“怕幻觉、怕不准、怕格式乱”。而原文里最有冲击力的一点,恰恰是近万字研究报告和财务模型都没有明显数据错误。这比单纯说“会生成 PPT”要有说服力得多。
Claude Code 到底是什么?为什么它会反复出现在这类测试里
很多人第一次接触 Claude Code,会以为它只是“命令行里的 Copilot”。其实完全不是一回事。
Copilot 这类工具更像即时补全:
- 你写一半,它帮你续一段
- 你卡住了,它给你一个函数模板
- 它主要盯着当前文件和当前光标附近
Claude Code 的定位更接近一个能自主推进工程任务的 Agent。它能做的事通常包括:
- 读多个文件,理解整个项目上下文
- 直接改代码、加文件、做跨文件重构
- 执行命令、跑测试、看报错再修
- 处理 Git 工作流
- 通过 MCP 接外部系统
- 在一些新能力下继续往后台任务和自动化流程延展
也正因为如此,很多人在测新模型编程能力时,都会自然把 Claude Code 当成一个很好的实验场。因为这里测到的不是“模型会不会写一段代码”,而是它在真实开发工作流里能不能完成任务。
官方目前常见的使用方式主要有两类:一类是走 Claude 订阅。根据官方价格页与 Claude Code 产品页,Pro 月付是 20 美元/月,年付折算 17 美元/月,已经包含 Claude Code;Max 从 100 美元/月 起,更高档位到 200 美元/月;如果是团队使用,还会有团队席位方案。另一类是走 API,按 token 消耗计费,更适合要把模型接进自己工作流的开发者。
不过说实话,官方订阅对国内用户不太友好——需要海外信用卡,网络环境也得折腾。如果嫌麻烦想找个更省事的渠道,可以看看 Code80,真实订阅帐号转 API,换个 endpoint 就能直接用,体验跟官方一样。详情可以到官网了解:code.ai80.vip
常见问题
1. MiniMax M2.7 这次最强的点到底是什么?
不是某个单项能力突然爆炸,而是它在长任务、工具调用和多阶段执行上的稳定性明显提高了。你会感觉它不只是“更聪明”,而是“更能把事情做完”。
2. PinchBench 这种龙虾榜能代表模型真实水平吗?
不能完全等同。它更像是在测 Agent 任务成功率,而不是通用智能的全部表现。但对于今天越来越多的自动化工作流来说,这类指标确实比传统问答 benchmark 更接近实际价值。
3. 它在编程场景里已经能直接拿来用了吗?
从这篇实测看,已经能进入日常使用区间了,尤其是前端、小型交互、结构化任务和带反馈修复的场景。不过复杂项目里,开发者依然需要做结果验证,不能完全放手不看。
4. 它目前最大的短板是什么?
原文里提到两个比较明显的问题:一是还不具备视觉理解能力;二是在部分复杂图表、外部内容直接读取这类场景里,工作流仍然有边界。
5. 为什么这篇测试会频繁用到 Claude Code?
因为 Claude Code 很适合拿来测模型在真实开发环境里的表现。你可以直接看它读文件、写代码、修 bug、调用工具时到底顺不顺,而不只是看一段静态代码生成结果。
6. 国内用户怎么更方便地把 Claude Code 接进自己的工作流?
如果你已经习惯用 API 方式,国内用户可以通过 Code80 更方便地接入使用。
评论前必须登录!
立即登录 注册