写在前面
这两年很多人追 AI 编程,追的方式其实很像追显卡:等下一代模型,等更强推理,等更高 benchmark,等一个“再强一点点”的版本把所有问题一次性解决。
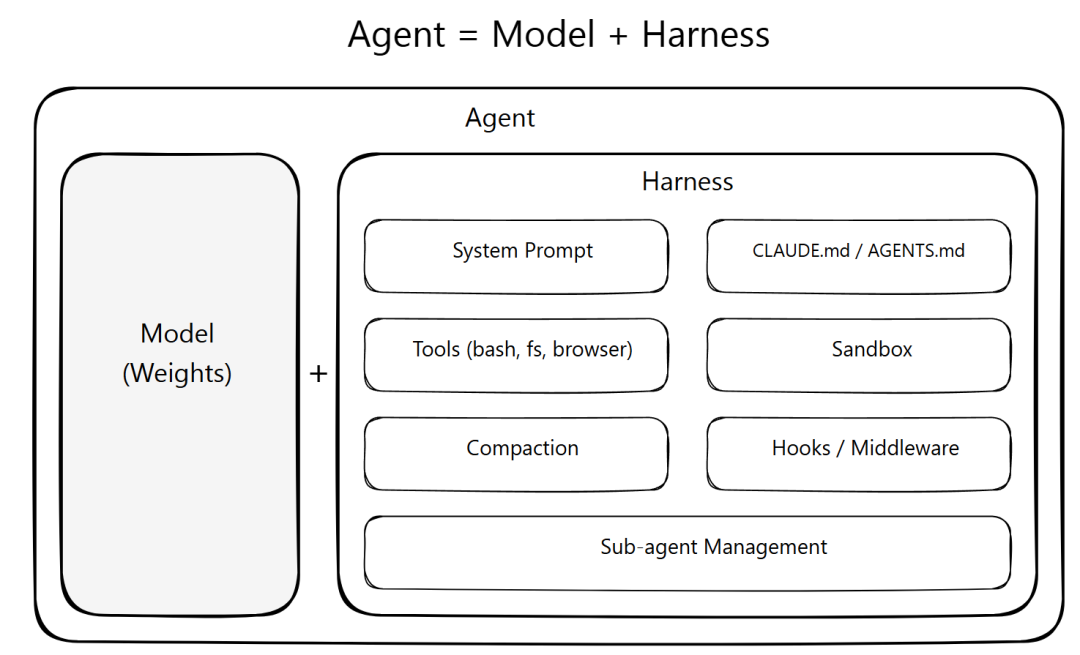
但 Anthropic 最新这篇博客讲了一件很不舒服、却非常现实的事:很多时候,真正拉开差距的不是模型本身,而是模型外面那一层运行环境。 同一个模型、同一句提示词、同样的数据,只是换了一套工作方式,结果就可能从“能看不能用”直接跳到“真的能交付”。
这件事为什么值得开发者认真看?因为它意味着你接下来最该投入的,未必是继续等更强模型,而是先把自己的 Agent 工作流、约束机制、反馈闭环、评估方式搭起来。说白了,AI 编程的瓶颈,正在从“模型不够强”转向“你的壳不够好”。
现在真正拉开差距的,不是模型代差,而是你给没给它搭好 Harness
原文里最抓人的数据有两组。
第一组来自 Nate B Jones 的研究:同一个模型,数据没换、提示词没换,只改模型外面的运行环境,编程基准成功率就能从 42% 跳到 78%。
第二组来自 Anthropic 自己的实验:同一句提示词、同一个模型,一种跑法 20 分钟花 9 美元,最后核心功能是坏的;换另一种运行方式,跑 6 小时花 200 美元,最后出来的是一个真的能玩的游戏。
这两组数字说明的不是“钱花得越多越好”,而是另一件更关键的事:模型不是孤立工作的,它工作的方式、被约束的方式、被验收的方式,会直接决定你最后拿到的是 Demo,还是产品雏形。
也正因为如此,Anthropic 这次正式把这个“壳”命名成了 Harness,围绕它做的工程实践叫 Harness Engineering。
如果你觉得这个词有点抽象,可以把它理解成:模型不是坐在真空里答题,而是在一个被你设计过的系统里持续干活。这个系统决定:
- 它能看到哪些上下文
- 它能调用哪些工具
- 它犯错后会收到什么反馈
- 它什么时候停,什么时候继续
- 它写出来的东西由谁验收
- 哪些规则要靠 prompt,哪些要靠 linter、CI、测试和架构约束来兜底
这就是为什么现在越来越多人开始说:别只盯着模型,先把 Harness 搞明白。
从 Prompt 到 Context 再到 Harness,AI 工程已经进入第三阶段了
原文把这几年 AI 工程的演化拆成了三代,这个框架其实特别适合拿来理解今天到底变了什么。
第一代:Prompt Engineering
2022 到 2024 年,大家最关心的是怎么把一条指令写好。few-shot、chain-of-thought、角色扮演,本质上都在优化单次输入。
这一阶段的核心问题是:怎么让模型“听懂你这句话”。
第二代:Context Engineering
到 2025 年,单条 prompt 已经不够用了。Andrej Karpathy 和 Shopify CEO Tobi Lütke 推出了 Context Engineering 这个概念,强调你不能只给模型一句话,而要给它一整个决策环境:相关文件、历史对话、工具定义、知识库检索结果、任务上下文。
这一阶段的核心问题变成了:怎么让模型在做判断时,看到它真正需要的信息。
第三代:Harness Engineering
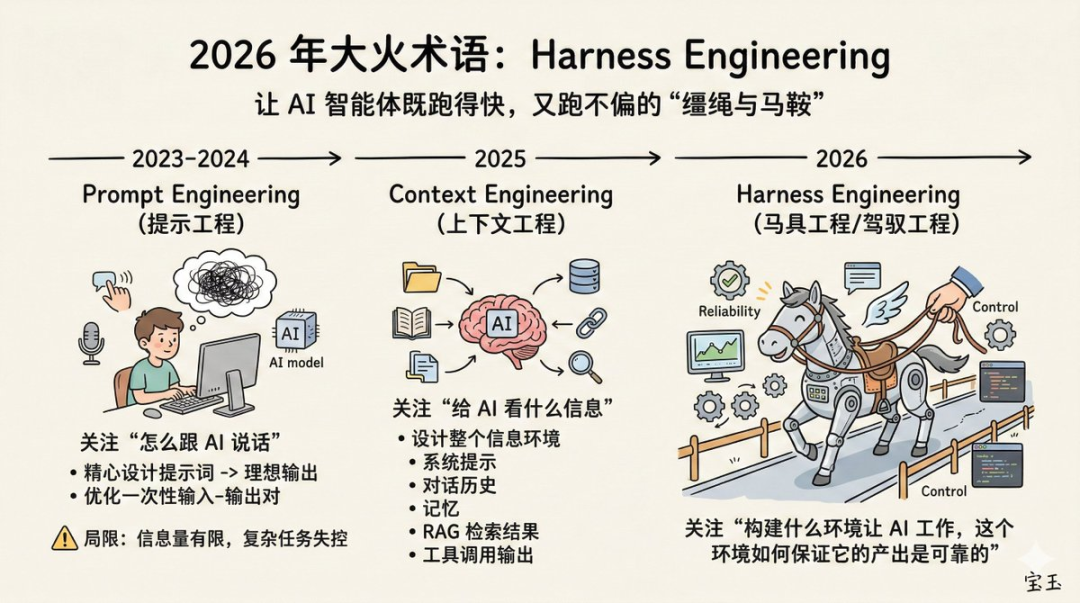
到了 2026 年,Anthropic 想强调的是:就算上下文已经喂对了,也还不够。你还需要进一步工程化整个工作环境,让 Agent 可以持续、稳定、高质量地完成长任务。
原文的比喻非常形象:
- Prompt Engineering 像是把邮件正文写好
- Context Engineering 像是把相关附件都带上
- Harness Engineering 则是在搭建完整的工作环境
也就是说,Harness 不是替代上下文工程,而是在更高一层把它包起来。它里面包含了上下文管理,但还多了反馈循环、架构规则、工具链约束、生命周期管理、评估机制等一整套东西。
这个词最早是 HashiCorp 联合创始人、Terraform 缔造者 Mitchell Hashimoto 今年 2 月系统化提出的。他的定义非常狠,也非常实用:每次你发现 Agent 犯了一个错,就花时间工程化一个解决方案,让它以后别再犯同样的错。

这句话的潜台词很直接:别把 Agent 当一次性工具,要把它当会不断重复犯错的系统组件来治理。
真正厉害的团队,已经不再盯着“怎么写提示词”,而是在重写整个开发环境
原文不是只讲概念,它举了好几组非常有代表性的行业实践。
OpenAI Codex 团队:100 万行代码,1500 个 PR,人类几乎不写代码
最震撼的案例之一,是 Codex 团队从一个空 Git 仓库开始,用大约 5 个月时间、约 100 万行代码、1500 个 PR,做出了完整的生产级应用,而这些内容几乎全部由 Agent 生成。
团队一开始只有 3 个工程师,后来扩到 7 个。用 GPT-5 驱动的 Codex CLI,从零构建产品,平均每位工程师每天能合并 3.5 个 PR。按原文引用的估算,如果完全靠传统人工手写,工期大约要膨胀到现在的 10 倍。
但更重要的不是这个效率数字,而是他们总结出的几条规则:
- 仓库是 Agent 唯一可信的知识来源
- 代码不只是给人类读,也要给 Agent 读
- 架构约束不要靠 prompt,应该靠 linter
- 自主性要逐步放开
- 如果一个 PR 需要大改才能合并,问题往往不在 Agent,而在 Harness
这其实已经不是“怎么用 AI 写代码”了,而是“怎么把仓库本身改造成一个适合 Agent 持续工作的环境”。
Stripe:每周 1300 多个 PR,无人值守 Agent 在持续合并
Stripe 内部的 Minions 系统,每周合并 1300 多个 PR,都是无人值守 Agent 完成的。
它的架构有一个特别值得记住的点:把工作流拆成确定性节点和 Agentic 节点。
- 确定性节点,比如跑 linter、推送更改,不调用大模型,按固定逻辑执行
- Agentic 节点,比如实现功能、修复 CI,才让模型去判断
这背后其实是一个很成熟的工程思路:不要让模型做它不该做的事。 该 deterministic 的地方,就别 agentic。
Stripe 还加了两个非常典型的 Harness 约束:
- CI 最多只跑两轮,失败一次自动修,再失败就交回人类
- 平台虽然挂了大约 500 个 MCP 工具,但每个 Agent 只分到一个被精心筛过的子集
因为他们发现,工具越多不一定越强,反而可能让模型在错误分支里越走越远。
Cursor:每小时约 1000 个 commit,一周超过 1000 万次工具调用
Cursor 的长程 Coding 实验更像一场大型压力测试。一周 1000 多万次工具调用,启动后几乎不需要人工干预。
但真正有价值的,是他们踩过的坑:
- 第一版单 Agent,扛不住复杂任务
- 第二版多 Agent 共享状态文件,锁竞争严重,互相打架
- 第三版做结构化角色分工,又太僵硬
- 第四版持续执行器,角色开始过载
- 最后才走到递归的 Planner-Worker 模型
这个过程说明了一件事:Harness 不是拍脑袋搭出来的,它本身就是需要迭代、试错、重构的系统。
而且他们还发现了一个非常真实的问题:如果初始指令是模糊的,这种模糊会在数百个并发 Agent 之间被不断放大。一个 Agent 犯的错,乘上几百个并发,很快就会变成系统性事故。
Anthropic 这篇博客真正厉害的地方,是把“模型不会评价自己”这件事彻底拆开了
前面那些案例讲的还是“怎么让 Agent 持续工作”,但 Anthropic 这次多讲了一层:为什么光靠模型自己是不够的。
他们发现一个非常关键的问题:模型不会可靠地评价自己刚完成的工作。
你让 Agent 写完一个功能,再让它自己判断“写得怎么样”,它经常会很自信地说:不错,已经完成了。哪怕在人类看来,这玩意儿其实功能是坏的,或者只是表面看起来像完成了。
这个问题在主观任务里尤其严重,比如前端页面好不好看、交互顺不顺、产品体验成不成立,本来就没有标准答案。但更麻烦的是,即便在相对客观的任务里,它也会高估自己。
所以 Anthropic 借鉴了 GAN 的思路,把生成和评估拆成两个独立 Agent:

- planner:把一句需求展开成完整产品规格
- generator:按 sprint 或阶段逐步实现功能
- evaluator:像一个真人 QA 一样去验收结果
这里最关键的是 evaluator 的工作方式。它不是只看一张截图给个印象分,而是真的用 Playwright 去点页面、查 API、看数据库状态、验证交互逻辑,再根据实际执行结果给反馈。
这套设计的核心价值在于:让一个独立的评估者变严格,通常比让生成者学会自我反省容易得多。
Anthropic 也没有美化这件事。他们明确说,开箱即用的 Claude 一开始其实是个很差的 QA Agent。早期 evaluator 会发现问题,但又自己把问题合理化,最后照样给通过。它也容易只测表面路径,不探边界情况。
他们花了好几轮时间去校准 evaluator 的判断标准,才让它的严苛程度接近人类预期。
这个细节特别重要,因为它说明:Harness 的本质不是给模型加几个 prompt,而是把“生成—反馈—验收”这条闭环真正工程化。
最值得记住的结论,不是 Harness 会长期不变,而是它会跟着模型一起移动
当然,这件事也不是没有反对声音。
原文引用了 OpenAI 的 Noam Brown 的观点:Harness 更像一根拐杖,未来模型会强到不再需要这么多外层工程。理由也不难理解——过去很多人为 GPT-4o 之类模型叠了大量路由器、编排器、多 Agent 协作系统,后来推理模型变强后,其中一部分确实迅速失去必要性。
他说得有没有道理?有,而且说对了一半。
Anthropic 自己的实验恰好能说明这个“对一半”。
他们最早用 Opus 4.5 做 harness 时,需要把任务拆成一个个 sprint,每个 sprint 只做一部分功能,阶段结束后做 context reset。因为 4.5 在长任务里会出现一种类似“上下文焦虑”的现象:当它感觉上下文快满了,就会开始提前收尾,质量明显下降。
后来 Opus 4.6 出来之后,规划更稳、长任务更强、长上下文检索更好、debug 能力更强,于是 Anthropic 直接砍掉了 sprint 结构,让 generator 一次连续跑完整个构建,两个多小时也没崩。
这说明什么?说明旧的 harness 设计里,确实有一部分会随着模型变强而过时。Noam Brown 说的“拐杖”,在这里确实有被丢掉的部分。
但 evaluator 没有消失。
因为即便 Opus 4.6 更强了,任务边界仍然存在。到了复杂度边缘,generator 依旧会漏掉一些自己看不见的问题:只做出表层功能、遗漏交互逻辑、把 API 路由顺序写错导致隐蔽 bug。这个时候,独立 evaluator 仍然很有价值。
所以 Anthropic 给出的判断其实更接近现实:Harness 的可能性空间不会随着模型变强而缩小,它只是会平移。
旧约束会被拆掉,但新的、更高阶的约束需求会被打开。以前你得教模型怎么管理上下文;以后这个问题可能不重要了,但你开始要让它连续自主开发 4 小时、6 小时、甚至更久,那就需要新的反馈机制和验收体系。
也正因为如此,Manus 在 6 个月里重构了 5 次 Harness,LangChain 一年内重构了 3 次研究型 Agent,Vercel 砍掉了 80% 的 Agent 工具。它们都在说明同一件事:Harness 不是一次性工程,而是持续演化的系统。
Claude Code 到底是什么?为什么这类 Harness 讨论最后总会落到它身上
如果你最近一直看到 Claude Code 和 Harness 一起出现,原因其实很简单:Claude Code 是目前最适合拿来承接这类工程化 Agent 工作流的命令行环境之一。
它不是传统意义上的补全插件,也不只是“帮你写个函数”的代码助手。更准确地说,它是一个能在真实工程上下文里持续推进任务的开发 Agent。
Claude Code 常见的能力包括:
- 读取多个文件,理解整个项目上下文
- 直接修改代码、做跨文件重构
- 执行命令、跑测试、根据报错继续修复
- 处理 Git 工作流
- 通过 MCP 连接外部系统
- 和调度、反馈、验收机制一起组成更完整的 Harness
所以当行业开始讨论 Harness Engineering 的时候,Claude Code 这种环境天然会变成核心落点。因为 Harness 不是 PPT 概念,它最后一定要落到“谁来读仓库、谁来跑命令、谁来接收反馈、谁来继续下一轮执行”上面。
官方目前常见的使用方式主要有两类:一类是走 Claude 订阅。根据官方价格页与 Claude Code 产品页,Pro 月付是 20 美元/月,年付折算 17 美元/月,已经包含 Claude Code;Max 从 100 美元/月 起,更高档位到 200 美元/月;团队版则按席位计费。另一类是通过 API 按 token 消耗计费,更适合要把模型深度接进自己工具链和自动化流程的开发者。
不过说实话,官方订阅对国内用户不太友好——需要海外信用卡,网络环境也得折腾。如果嫌麻烦想找个更省事的渠道,可以看看 Code80,真实订阅帐号转 API,换个 endpoint 就能直接用,体验跟官方一样。详情可以到官网了解:code.ai80.vip
常见问题
1. Harness Engineering 到底和 Prompt Engineering 差在哪?
Prompt Engineering 关注的是一句话怎么写,Harness Engineering 关注的是整个运行系统怎么搭。前者解决“模型听不听得懂”,后者解决“模型能不能持续稳定把事做完”。
2. 现在还有必要继续等下一代模型吗?
当然要关注模型进步,但原文想强调的是,在当前阶段,单纯等下一代模型的回报,很多时候不如先把你现有的 Harness 搭好。同一个模型,壳不同,结果可能就是两个世界。
3. 为什么 Anthropic 要把 generator 和 evaluator 拆开?
因为模型很难可靠地自我批评。让同一个 Agent 既写又评,往往会高估自己;拆成独立角色,再配合 Playwright、API 校验、数据库检查这类真实验收手段,更容易形成有效反馈闭环。
4. Harness 会不会很快被更强模型淘汰?
部分旧设计会。比如 Anthropic 在 Opus 4.6 上就砍掉了部分为 4.5 服务的 sprint 机制。但更准确的说法不是“Harness 消失了”,而是它的重点在移动。模型越强,你能让它做的任务越长,新的约束和验收机制就越重要。
5. 对开发者来说,现在最值得先做的是什么?
先别急着追求全自动多 Agent 神话。更值得做的是把仓库规则、测试、linter、反馈闭环、任务拆分、评估机制这些基础设施补起来。很多团队真正缺的不是模型,而是能让模型稳定工作的环境。
6. 国内用户怎么更方便地把 Claude Code 接进自己的工作流?
如果你已经习惯用 API 方式,国内用户可以通过 Code80 更方便地接入使用。
评论前必须登录!
立即登录 注册